Charakterystyka systemu BIOS dla HPC z procesorami Intel Cascade Lake
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Artykuł napisany przez Varuna Bawę, Savithę Pareek i Ashisha K. Singha z HPC and AI Innovation Lab w kwietniu 2019 r.
Resolution
Wraz z wprowadzeniem na rynek procesorów Intel Xeon® Scalable drugiej generacji (architektura o nazwie kodowej "Cascade Lake") firma Dell EMC zaktualizowała serwery PowerEdge 14. generacji, aby zapewnić większą liczbę rdzeni i większą szybkość pamięci, co korzystnie wpływa na aplikacje HPC.
W tym blogu przedstawiono pierwszy zestaw wyników i omówiono wpływ różnych opcji dostrajania systemu BIOS dostępnych w serwerach Dell EMC PowerEdge C6420 z najnowszymi procesorami Intel Xeon® Cascade Lake na niektóre testy porównawcze i aplikacje HPC. Poniżej znajduje się krótki opis procesora Cascade Lake, opcji systemu BIOS i aplikacji HPC wykorzystanych w tym opracowaniu.
Cascade Lake to następca procesora Intel Skylake. Procesor Cascade Lake obsługuje do 28 rdzeni, sześć kanałów pamięci DDR4 z prędkością do 2933 MT/s. Podobnie jak Skylake, Cascade Lake obsługuje dodatkową moc wektoryzacji dzięki zestawowi instrukcji AVX512 pozwalającemu na 32 DP FLOP/cykl. Cascade Lake wprowadza instrukcje wektorowej sieci neuronowej (VNNI), które przyspieszają działanie obciążeń roboczych związanych ze sztuczną inteligencją i DL, takich jak klasyfikacja obrazów, rozpoznawanie mowy, tłumaczenie języka, wykrywanie obiektów i inne. Funkcja VNNI obsługuje również instrukcje 8-bitowe w celu zwiększenia wydajności wnioskowania.
Cascade Lake zawiera sprzętowe środki zaradcze dla niektórych luk w zabezpieczeniach kanału bocznego. Oczekuje się, że może to poprawić wydajność obciążeń roboczych pamięci masowej. Zapoznaj się z przyszłymi badaniami Laboratorium Innowacji.
Ponieważ procesory Skylake i Cascade Lake są zgodne z gniazdami, pokrętła regulacji procesorów dostępne w systemie BIOS są podobne w obu generacjach procesorów. W tym badaniu przeanalizowano następujące opcje dostrajania systemu BIOS, podobne do prac opublikowanych w przeszłości na procesorze Skylake.
 OS – PerformancePerWattOS
OS – PerformancePerWattOS  DAPC – PerformancePerWattDAPC
DAPC – PerformancePerWattDAPC
Sub-NUMA Clustering: SNC = 0(SNC = wyłączone): SNC = 1(SNC = włączone: Sformatowane jako przeplatane na wykresach)
SW — Software Prefetcher: SW = 0 (SW = Wyłączone): SW = 1 (SW = Enabled)
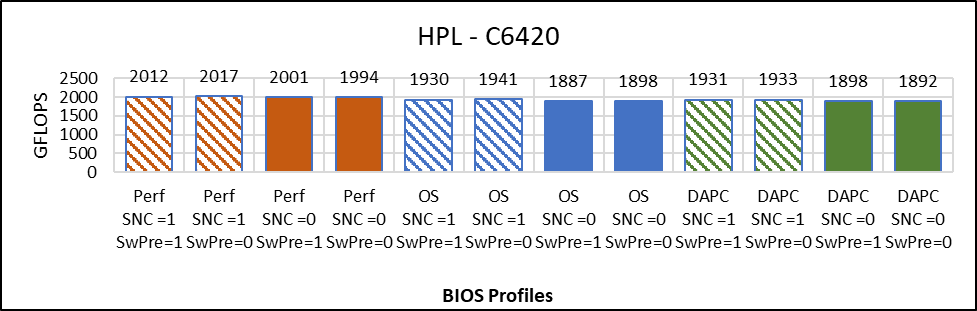
Rysunek 2 porównuje wynik HPL z rozmiarem problemu = 90%, tj. N=144476 w różnych opcjach systemu BIOS. Wykres przedstawia bezwzględne gigaflopy uzyskane podczas korzystania z HPL w różnych konfiguracjach systemu BIOS. Te uzyskane gigaflopy są wykreślane na osi y, im wyżej, tym lepiej.
Poniżej obserwacje z wykresu:
Rysunek 3 porównuje wynik STREAM w różnych konfiguracjach systemu BIOS.
Wykres przedstawia przepustowość pamięci w gigabajtach na sekundę uzyskaną podczas korzystania z triady STREAM. Uzyskana przepustowość pamięci (GB/s) jest wykreślana na osi y, im wyższa, tym lepiej. Konfiguracja systemu BIOS powiązana z określonymi wartościami gigabajtów na sekundę jest wykreślana na osi x.
Poniżej obserwacje z wykresu:
Rysunek 4 przedstawia wynik przepustowości pamięci triady strumieniowej w takiej konfiguracji. Przepustowość pamięci systemu wynosi ~220 GB/s. Gdy 20 rdzeni w gnieździe lokalnym uzyskuje dostęp do pamięci lokalnej, przepustowość pamięci wynosi ~ 109 GB/s - połowa pełnej przepustowości systemu. Połowa tego, ~56 GB/s, to przepustowość pamięci 10 wątków w tym samym węźle NUMA uzyskujących dostęp do pamięci lokalnej, a w jednym węźle NUMA dostęp do pamięci należącej do drugiego węzła NUMA w tym samym gnieździe. Występuje spadek przepustowości pamięci o 42% do ~33 GB/s, gdy wątki uzyskują dostęp do pamięci zdalnej przez łącze QPI w gnieździe zdalnym. Informuje nas to o znacznym spadku przepustowości w trybie SNC, gdy dane nie są lokalne.
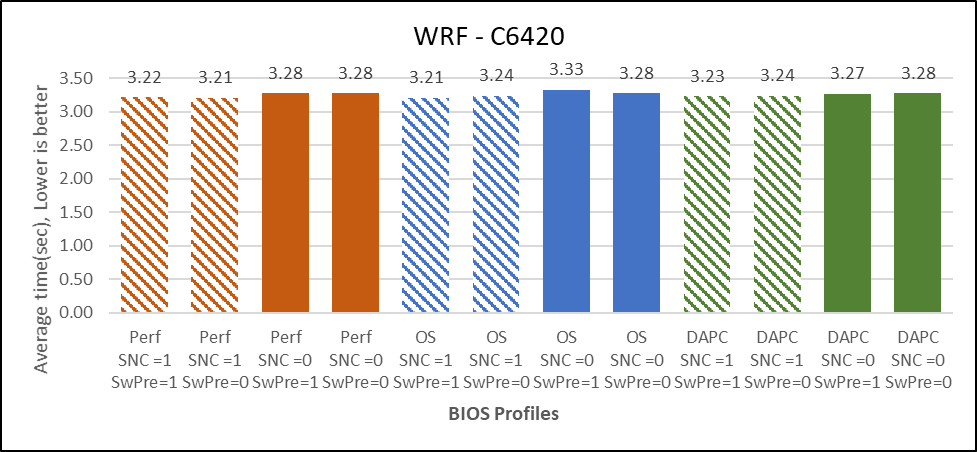
Rysunek 5 porównuje wynik WRF w różnych opcjach systemu BIOS. Użyty zestaw danych to conus2.5km z domyślnym plikiem "namelist.input".
Wykres przedstawia bezwzględny średni przedział czasowy w sekundach uzyskany podczas korzystania z zestawu danych WRF-conus2,5km w różnych konfiguracjach systemu BIOS. Uzyskany średni krok czasowy jest wykreślany na osi y, im niższy, tym lepiej. Profile względne skojarzone z określonymi wartościami średniego kroku czasowego są wykreślane na osi x.
Poniżej obserwacje z wykresu:

Na rysunku od 6 do 9 przedstawiono ocenę solvera uzyskaną podczas uruchamiania narzędzia Fluent- odpowiednio z zestawem danych Ice_2m, Combustor_12m, Aircraft_Wing_14m i Exhaust_System_33m. Uzyskana ocena solvera jest wykreślana na osi y, im wyższa, tym lepiej. Profile względne powiązane z określonymi wartościami średniego czasu są wykreślane na osi x.
Poniżej znajdują się ogólne obserwacje z powyższych wykresów:
W tym opracowaniu nie omówiono funkcji RAS pamięci o nazwie Adaptive Double DRAM Device Correction (ADDDC), która jest dostępna, gdy system jest skonfigurowany z pamięcią wyposażoną w pamięć DRAM x4 (moduły DIMM 32 GB, 64 GB). Funkcja ADDDC nie jest dostępna, jeśli komputer ma moduły DIMM x8 (8 GB, 16 GB) i nie ma znaczenia w tych konfiguracjach. W przypadku obciążeń roboczych HPC zaleca się ustawienie ADDDC jako wyłączone, jeśli jest dostępne jako opcja dostrajalna.
W tym blogu przedstawiono pierwszy zestaw wyników i omówiono wpływ różnych opcji dostrajania systemu BIOS dostępnych w serwerach Dell EMC PowerEdge C6420 z najnowszymi procesorami Intel Xeon® Cascade Lake na niektóre testy porównawcze i aplikacje HPC. Poniżej znajduje się krótki opis procesora Cascade Lake, opcji systemu BIOS i aplikacji HPC wykorzystanych w tym opracowaniu.
Cascade Lake to następca procesora Intel Skylake. Procesor Cascade Lake obsługuje do 28 rdzeni, sześć kanałów pamięci DDR4 z prędkością do 2933 MT/s. Podobnie jak Skylake, Cascade Lake obsługuje dodatkową moc wektoryzacji dzięki zestawowi instrukcji AVX512 pozwalającemu na 32 DP FLOP/cykl. Cascade Lake wprowadza instrukcje wektorowej sieci neuronowej (VNNI), które przyspieszają działanie obciążeń roboczych związanych ze sztuczną inteligencją i DL, takich jak klasyfikacja obrazów, rozpoznawanie mowy, tłumaczenie języka, wykrywanie obiektów i inne. Funkcja VNNI obsługuje również instrukcje 8-bitowe w celu zwiększenia wydajności wnioskowania.
Cascade Lake zawiera sprzętowe środki zaradcze dla niektórych luk w zabezpieczeniach kanału bocznego. Oczekuje się, że może to poprawić wydajność obciążeń roboczych pamięci masowej. Zapoznaj się z przyszłymi badaniami Laboratorium Innowacji.
Ponieważ procesory Skylake i Cascade Lake są zgodne z gniazdami, pokrętła regulacji procesorów dostępne w systemie BIOS są podobne w obu generacjach procesorów. W tym badaniu przeanalizowano następujące opcje dostrajania systemu BIOS, podobne do prac opublikowanych w przeszłości na procesorze Skylake.
Ustawienia procesora:
- Wstępne pobieranie przyległej pamięci podręcznej: Mechanizm Adjacent Cache-Line Prefetch pozwala na automatyczne sprzętowe prefetch, działa bez ingerencji programisty. Gdy ta opcja jest włączona, mieści dwie 64-bajtowe linie pamięci podręcznej w sektorze 128-bajtowym, niezależnie od tego, czy zażądano dodatkowej linii pamięci podręcznej, czy nie.
- Wstępne pobieranie oprogramowania: Pozwala to uniknąć przestoju, ładując dane do pamięci podręcznej, zanim będą potrzebne. Example: Aby wstępnie pobrać dane z pamięci głównej do pamięci podręcznej L2 znacznie przed użyciem za pomocą instrukcji wstępnego pobierania L2, a następnie wstępnie pobrać dane z pamięci podręcznej L2 do pamięci podręcznej L1 tuż przed użyciem za pomocą instrukcji wstępnego pobierania L1. W tym miejscu, po włączeniu tej opcji, procesor będzie wstępnie pobierał dodatkowy wiersz pamięci podręcznej dla każdego żądania pamięci.
- SNC (klaster sub-Numa): Włączenie SNC jest podobne do podzielenia pojedynczego gniazda na dwie domeny NUMA, z których każda ma połowę rdzeni fizycznych i połowę pamięci gniazda. Jeśli brzmi znajomo, jest podobny pod względem użyteczności do opcji Cluster-on-Die , która była dostępna w procesorach Intel Xeon E5-2600 v3 i v4. SNC jest implementowane inaczej niż COD, a te zmiany poprawiają zdalny dostęp do gniazd w Cascade Lake w porównaniu z poprzednimi generacjami, które korzystały z opcji Cluster-on-Die. Na poziomie systemu operacyjnego serwer z dwoma gniazdami procesora z włączoną funkcją SNC będzie wyświetlał cztery domeny NUMA. Dwie domeny będą bliżej siebie (na tym samym gnieździe), a pozostałe dwie będą w większej odległości, po drugiej stronie UPI do zdalnego gniazda. Można to zaobserwować za pomocą narzędzi systemu operacyjnego, takich jak: numactl –H i jest zilustrowany na rysunku 1.
Rysunek 1. Układ węzłów NUMA
Profile systemów:
Profile systemowe to metaopcje, które z kolei ustawiają wiele opcji systemu BIOS skoncentrowanych na wydajności i zarządzaniu energią, takich jak tryb Turbo, Cstate, C1E, zarządzanie Pstate, częstotliwość pozardzeniowa itp. Różne profile systemów porównane w tym badaniu obejmują:- Performance (Wydajność).
- WydajnośćPerWattDAPC
- WydajnośćPerWattOS
| Applications | Domena | Wersja | Punkt odniesienia |
|---|---|---|---|
| Wysokowydajny pakiet liniowy (HPL) | Obliczenia-Rozwiąż gęsty układ równań liniowych | Z Intel MKL — aktualizacja 1 z 2019 r. | Rozmiar problemu 90%, 92% i 94% całkowitej pamięci |
| Strumienia | Przepustowość pamięci | 5.4 | Triady |
| WRF | Badania i prognozowanie pogody | 3.9.1 | Stożek 2,5 km |
| ANSYS® Płynny® | Dynamika płynów | 19.2 | Ice_2m, Combustor_12m, Aircraft_wing_14m, Exhaust_System_33m |
Tabela 1: Aplikacje i testy porównawcze
| Składniki | Szczegóły |
|---|---|
| Serwer | Serwer PowerEdge C6420 |
| Procesor | Intel® Xeon® Gold 6230 CPU @ 2.1GHz, 20 rdzeni |
| Pamięć | 192 GB – 12 x 16 GB pamięci DDR4 2933 MT/s |
| System operacyjny | Redhat Enterprise Linux 7.6 |
| Jądro | 3.10.0-957.el7.x86_64 |
| Kompilator | Intel Parallel Studio Cluster Edition_2019_Update_1 |
Tabela 2 Konfiguracja serwera
Wszystkie przedstawione tutaj wyniki są oparte na testach z jednym serwerem; Wydajność na poziomie klastra będzie zależna od wydajności pojedynczego serwera. Do porównania skuteczności użyto następujących wskaźników:- Stream — wynik triady zgłoszony przez test porównawczy strumienia.
- HPL – GFLOP/sekundę.
- Fluent — ocena dodatku Solver zgłoszona przez firmę Fluent.
- WRF – Średni przedział czasowy obliczony dla ostatnich 719 interwałów dla Conus 2.5km
Testy porównawcze i wyniki aplikacji
Skróty notacji wykresów:
Profile systemów:
Perf – Performance OS – PerformancePerWattOS DAPC – PerformancePerWattDAPCSub-NUMA Clustering: SNC = 0(SNC = wyłączone): SNC = 1(SNC = włączone: Sformatowane jako przeplatane na wykresach)
SW — Software Prefetcher: SW = 0 (SW = Wyłączone): SW = 1 (SW = Enabled)
Rysunek 2. Wysokowydajny pakiet Linpack
Rysunek 2 porównuje wynik HPL z rozmiarem problemu = 90%, tj. N=144476 w różnych opcjach systemu BIOS. Wykres przedstawia bezwzględne gigaflopy uzyskane podczas korzystania z HPL w różnych konfiguracjach systemu BIOS. Te uzyskane gigaflopy są wykreślane na osi y, im wyżej, tym lepiej.
Poniżej obserwacje z wykresu:
- Różnica w wydajności HPL mniejsza niż 1% dzięki wstępnemu pobieraniu oprogramowania.
- Brak większego wpływu SNC na wydajność HPL (0,5% lepiej z SNC=Disabled).
- Wydajność profilu systemu jest nawet o 6% lepsza w porównaniu z systemem operacyjnym i DAPC.
Rysunek 3. Strumienia
Rysunek 3 porównuje wynik STREAM w różnych konfiguracjach systemu BIOS.
Wykres przedstawia przepustowość pamięci w gigabajtach na sekundę uzyskaną podczas korzystania z triady STREAM. Uzyskana przepustowość pamięci (GB/s) jest wykreślana na osi y, im wyższa, tym lepiej. Konfiguracja systemu BIOS powiązana z określonymi wartościami gigabajtów na sekundę jest wykreślana na osi x.
Poniżej obserwacje z wykresu:
- Nawet o 3% lepsza przepustowość pamięci przy włączonej funkcji SNC=.
- Niewielkie odchylenia w wydajności ze względu na wstępne pobieranie oprogramowania w przepustowości pamięci STREAM.
- Brak odchyleń między profilami systemowymi.
Rysunek 4. Przepustowość pamięci — SNC
Rysunek 4 przedstawia wynik przepustowości pamięci triady strumieniowej w takiej konfiguracji. Przepustowość pamięci systemu wynosi ~220 GB/s. Gdy 20 rdzeni w gnieździe lokalnym uzyskuje dostęp do pamięci lokalnej, przepustowość pamięci wynosi ~ 109 GB/s - połowa pełnej przepustowości systemu. Połowa tego, ~56 GB/s, to przepustowość pamięci 10 wątków w tym samym węźle NUMA uzyskujących dostęp do pamięci lokalnej, a w jednym węźle NUMA dostęp do pamięci należącej do drugiego węzła NUMA w tym samym gnieździe. Występuje spadek przepustowości pamięci o 42% do ~33 GB/s, gdy wątki uzyskują dostęp do pamięci zdalnej przez łącze QPI w gnieździe zdalnym. Informuje nas to o znacznym spadku przepustowości w trybie SNC, gdy dane nie są lokalne.
Rysunek 5. WRF
Rysunek 5 porównuje wynik WRF w różnych opcjach systemu BIOS. Użyty zestaw danych to conus2.5km z domyślnym plikiem "namelist.input".
Wykres przedstawia bezwzględny średni przedział czasowy w sekundach uzyskany podczas korzystania z zestawu danych WRF-conus2,5km w różnych konfiguracjach systemu BIOS. Uzyskany średni krok czasowy jest wykreślany na osi y, im niższy, tym lepiej. Profile względne skojarzone z określonymi wartościami średniego kroku czasowego są wykreślane na osi x.
Poniżej obserwacje z wykresu:
- O 2% lepsza wydajność przy SNC=Enabled.
- Brak różnicy w wydajności dla opcji Pobieranie z wyprzedzeniem włączone i wyłączone.
- Profil wydajności jest o 1% lepszy niż profil PerformancePerWattDAPC
Na rysunku od 6 do 9 przedstawiono ocenę solvera uzyskaną podczas uruchamiania narzędzia Fluent- odpowiednio z zestawem danych Ice_2m, Combustor_12m, Aircraft_Wing_14m i Exhaust_System_33m. Uzyskana ocena solvera jest wykreślana na osi y, im wyższa, tym lepiej. Profile względne powiązane z określonymi wartościami średniego czasu są wykreślane na osi x.
Poniżej znajdują się ogólne obserwacje z powyższych wykresów:
- Do 4% lepsza wydajność z SNC=Enabled.
- Brak wpływu wstępnego pobierania oprogramowania na wydajność.
- Nawet o 2% lepsza wydajność dzięki profilowi wydajności w porównaniu z profilami DAPC i systemem operacyjnym.
Wnioski
W tym badaniu oceniliśmy wpływ różnych opcji dostrajania systemu BIOS na wydajność podczas korzystania z procesora Intel Xeon Gold 6230. Obserwując wydajność różnych opcji systemu BIOS w różnych testach porównawczych i aplikacjach, dochodzę do następujących wniosków:- Wstępne pobieranie oprogramowania nie ma znaczącego wpływu na wydajność testowanych zestawów danych. W związku z tym zalecamy, aby opcja Software Prefetcher pozostała domyślna, tj. włączona
- Przy SNC=Enabled wzrost wydajności o 2–4% w Fluent i Stream, ok. 1% w WRF w porównaniu z SNC = Disabled. W związku z tym zalecamy włączenie SNC w celu uzyskania lepszej wydajności.
- Profil wydajności jest o 2–4% lepszy niż PerformancePerWattDAPC i PerformancePerWattOS. W związku z tym zalecamy profil wydajności dla HPC.
W tym opracowaniu nie omówiono funkcji RAS pamięci o nazwie Adaptive Double DRAM Device Correction (ADDDC), która jest dostępna, gdy system jest skonfigurowany z pamięcią wyposażoną w pamięć DRAM x4 (moduły DIMM 32 GB, 64 GB). Funkcja ADDDC nie jest dostępna, jeśli komputer ma moduły DIMM x8 (8 GB, 16 GB) i nie ma znaczenia w tych konfiguracjach. W przypadku obciążeń roboczych HPC zaleca się ustawienie ADDDC jako wyłączone, jeśli jest dostępne jako opcja dostrajalna.
Affected Products
High Performance Computing Solution Resources, Poweredge C4140, Red Hat Enterprise Linux Version 7Article Properties
Article Number: 000176921
Article Type: Solution
Last Modified: 16 Oct 2025
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.