PowerEdge: Installasjon av NVIDIA DataCenter GPU Manager (DCGM) og hvordan du kjører diagnostikk
Summary: Oversikt over hvordan du installerer DCGM-verktøyet (datacenter GPU manager) fra NVIDIA i Linux (RHEL/Ubuntu), og hvordan du kjører og forstår diagnostikkapplikasjonen.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Slik installerer du DCGM i Linux:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMBruker- og installasjonsveiledning for DCGM 3.3
Installere nyeste DCGM
Ved å laste ned og bruke programvaren godtar du å overholde vilkårene og betingelsene i NVIDIA DCGM-lisensen fullt ut.
Det anbefales å bruke den nyeste R450+ NVIDIA-datasenterdriveren som kan lastes ned fra siden for nedlastinger av NVIDIA-drivere.
Som anbefalt metode installerer du DCGM direkte fra CUDA-nettverksrepositoriet. Eldre DCGM-utgivelser er også tilgjengelige fra repositoriet.
Funksjoner av DCGM:
- Overvåking av GPU-atferd
- Administrasjon av GPU-konfigurasjon
- Oversikt over GPU-retningslinjene
- GPU-tilstand og -diagnostikk
- GPU-regnskap og prosessstatistikk
- NVSwitch konfigurasjon og overvåking
Hurtigstartinstruksjoner:
Ubuntu LTS
Konfigurere metadata for CUDA-nettverksrepositorium, GPG-nøkkel Eksemplet nedenfor er for Ubuntu 20.04 på x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Installer DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat
Konfigurere metadata for CUDA-nettverksrepositorium, GPG-nøkkel Eksemplet nedenfor er for RHEL 8 på x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Installer DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Slik kjører du DCGM:
Datacenter GPU Manager (DCGM) er en raskere måte for kunder å teste GPU-er fra operativsystemet. Det er fire nivåer av tester. Kjør nivå 4-testen for de mest dyptgående resultatene. Det tar vanligvis rundt 1 time og 30 minutter, men dette kan variere med GPU-type og antall. Verktøyet har muligheten for kunden å konfigurere testene til å kjøre automatisk og varsle kunden. Du finner mer om det fra denne linken. Vi vil anbefale å alltid bruke den nyeste versjonen, versjon 3.3 er den nyeste versjonen.
Eksempel 1:
Kommando: dcgmi diag -r 1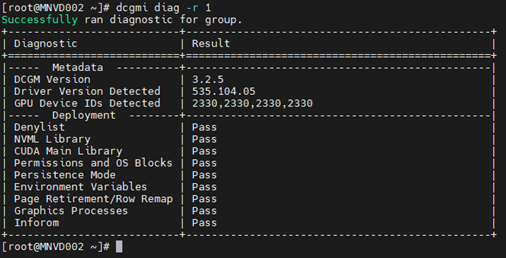
Eksempel 2:
Kommando: dcgmi diag -r 2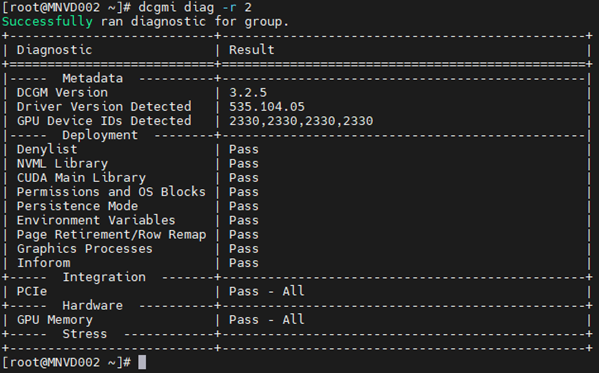
Eksempel 3:
Kommando: dcgm diag -r 3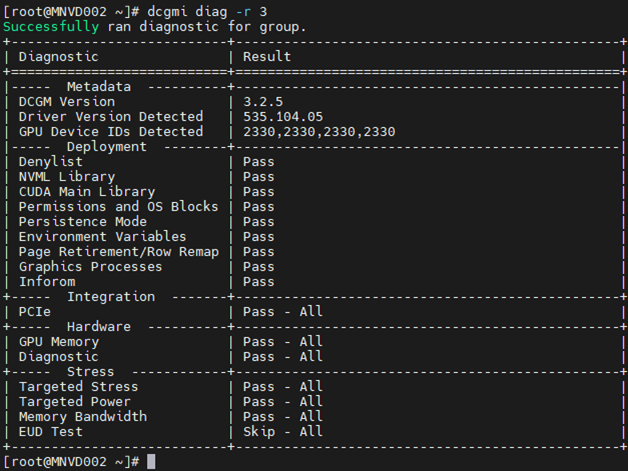
Eksempel 4:
Kommando: dcgm diag -r 4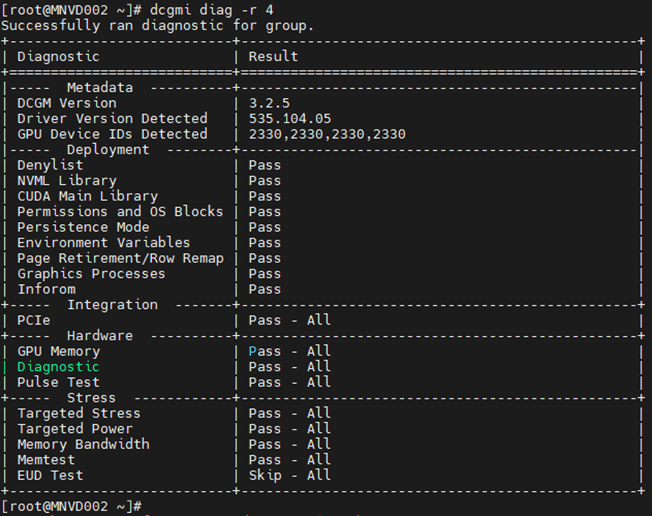
Diagnostikken kan gå glipp av enkelte feil på grunn av nisjevirksomheten, spesifisiteten for arbeidsbelastningen eller behovet for utvidede kjøretider for å oppdage dem.
Skulle du se en feil, undersøk den for å forstå innholdet i den fullt ut.
Begynn med å trekke nvidia-bug-report.sh -kommandoen (bare hjemme i Linux OS, ingen Windows) og gjennomgå utdatafilen.
Eksempler på feil ved minnevarsel:
Eksemplet nedenfor var aktivering og start av DCGM Health-skjermen med en påfølgende kontroll av alle installerte GPU-er på serveren. Du kan se at GPU3 produserte en advarsel om SBE-er (enkeltbitfeil) og driveren som ønsket å trekke tilbake den berørte minneadressen.
Kommando: dcgmi health -s a (dette starter helsevesenet og " a" forteller det å se alt)
Kommando: dcgmi health -c (dette sjekker alle oppdagede GPUer og rapporterer tilbake på dem)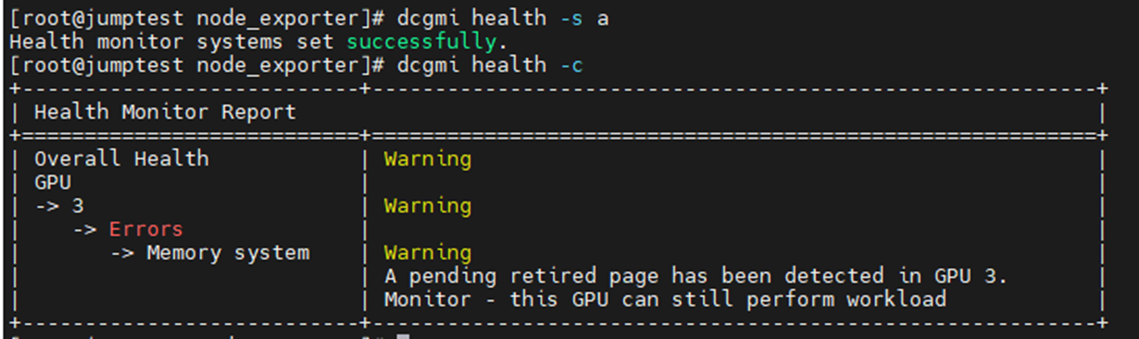
Et annet sted kan du se hva minnefeilene er fra utgangen nedenfor. Redigert for å vise bare de minnerelaterte elementene, kan vi se at GPU møtte 3,081 SBE-er, med et levetidsaggregat på 6,161. Vi ser også at GPU har en tidligere SBE pensjonert side med en ekstra ventende side svarteliste.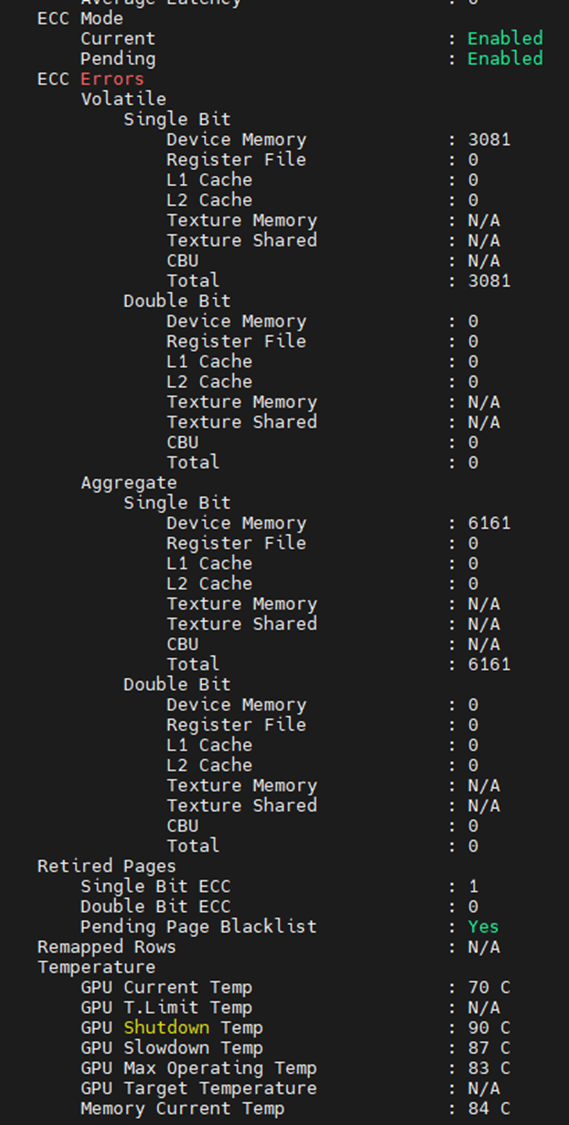
I tilfelle du ser minnefeil på GPUer, må selve enheten tilbakestilles. Dette oppnås ved en omstart av hele systemet eller utstedelse av nvidia-smi GPU-tilbakestilling mot enheten.
Når driveren er lastet ut, tilordnes den merkede svartelisteminneadressen. Når driveren laster inn på nytt, får GPU-en en ny adressetabell med de berørte adressene blokkert, tilsvarende PPR på Intel-prosessorer).
Unnlatelse av å tilbakestille GPU fører ofte til økning av flyktige og aggregerte tellere. Dette skyldes at GPU fortsatt tillater å bruke den berørte adressen, så hver gang den treffes, øker tellerne.
Hvis du fortsatt mistenker feil i én eller flere GPU-er, kjører du NVIDIA fieldiags (629-diagnostikk) for en mer dyptgående test på mål-GPU-en.
**SØRG FOR AT DU BRUKER DE NYESTE OG RIKTIGE FELTENE FOR GPU-EN SOM ER INSTALLERT, DETTE ER KRITISK**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.