PowerEdge: Instalação do NVIDIA DataCenter GPU Manager (DCGM) e como executar o diagnóstico
Summary: Visão geral sobre como instalar a ferramenta DCGM (Datacenter GPU Manager) da NVIDIA no Linux (RHEL/Ubuntu) e como executar e entender o aplicativo de diagnóstico.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Como instalar o DCGM no Linux:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMGuia do usuário e de instalação do DCGM 3.3
Instalando o DCGM
mais recente Ao fazer download e usar o software, você concorda em cumprir integralmente os termos e condições da Licença do DCGM da NVIDIA.
É recomendável usar o driver do data center NVIDIA R450+ mais recente que pode ser baixado na página de downloads de driver NVIDIA.
Como método recomendado, instale o DCGM diretamente dos repositórios de rede CUDA. Versões mais antigas do DCGM também estão disponíveis nos repositórios.
Características do DCGM:
- Monitoramento do comportamento da GPU
- Gerenciamento de configuração de GPU
- Supervisão da política de GPU
- Integridade e diagnóstico da GPU
- Contabilidade de GPU e estatísticas de processos
- Configuração e monitoramento do NVSwitch
Instruções de início rápido:
Ubuntu LTS
Configurar os metadados do repositório de rede CUDA, chave GPG O exemplo mostrado abaixo é para o Ubuntu 20.04 no x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Instale o DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat
Configurar os metadados do repositório de rede CUDA, chave GPG O exemplo mostrado abaixo é para RHEL 8 em x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Instale o DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Como executar o DCGM:
O Datacenter GPU Manager (DCGM) é uma maneira mais rápida de os clientes testarem GPUs de dentro do sistema operacional. Existem quatro níveis de testes. Execute o teste de nível 4 para obter os resultados mais detalhados. Normalmente, leva cerca de 1 hora e 30 minutos, mas isso pode variar de acordo com o tipo e a quantidade da GPU. A ferramenta tem a capacidade de o cliente configurar os testes para serem executados automaticamente e alertá-lo. Você pode encontrar mais sobre isso neste link. Aconselhamos sempre usar a versão mais recente, a versão 3.3 é a compilação mais recente.
Exemplo 1:
Comando: dcgmi diag -r 1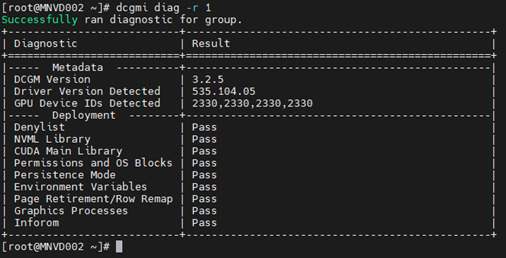
Exemplo 2:
Comando: dcgmi diag -r 2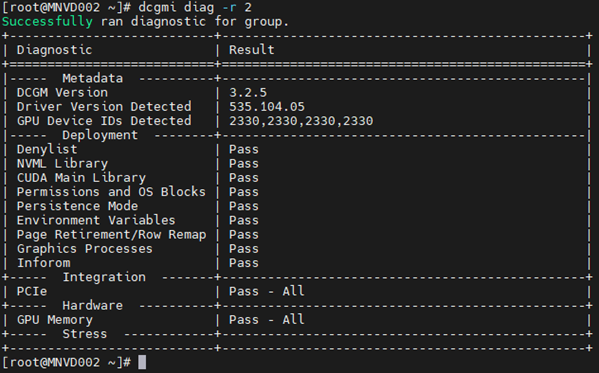
Exemplo 3:
Comando: dcgm diag -r 3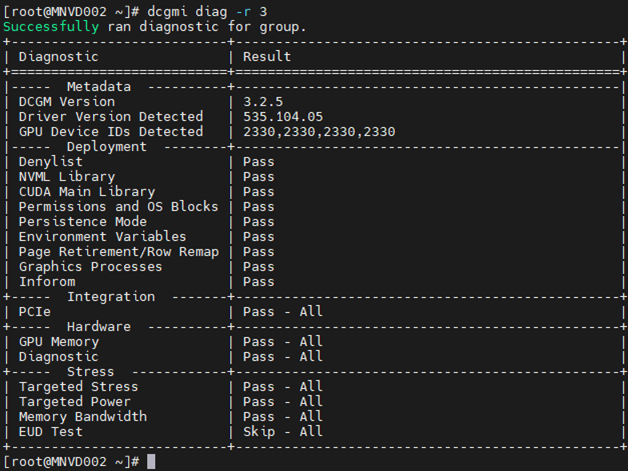
Exemplo 4:
Comando: dcgm diag -r 4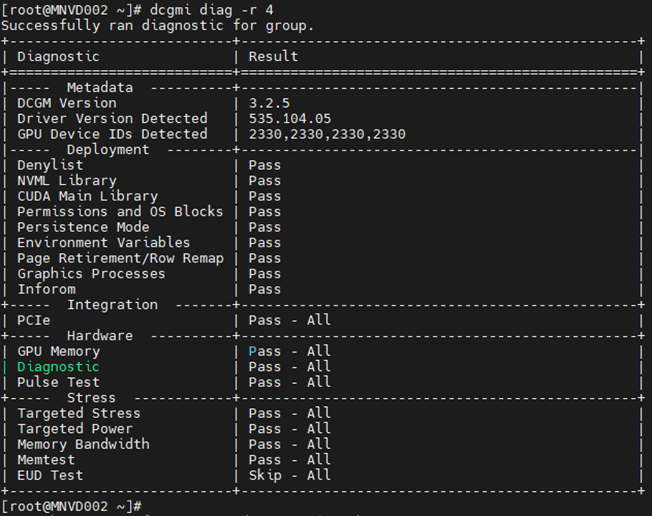
O diagnóstico pode perder alguns erros devido à sua natureza de nicho, à especificidade da carga de trabalho ou à necessidade de tempos de execução estendidos para detectá-los.
Se você vir um erro, investigue-o para entender completamente a natureza dele.
Comece puxando o nvidia-bug-report.sh (nativo apenas para o sistema operacional Linux, sem Windows) e analise o arquivo de saída.
Exemplos de uma falha de alerta de memória:
O exemplo abaixo estava ativando e iniciando o monitor de integridade do DCGM com uma verificação subsequente em todas as GPUs instaladas no servidor. Você pode ver que a GPU3 produziu um aviso sobre SBEs (erros de bit único) e o driver querendo desativar o endereço de memória afetado.
Comando: dcgmi health -s a (isso começa o serviço de saúde e o "a" manda ver tudo)
Comando: dcgmi health -c (isso verifica todas as GPUs detectadas e relata sobre elas)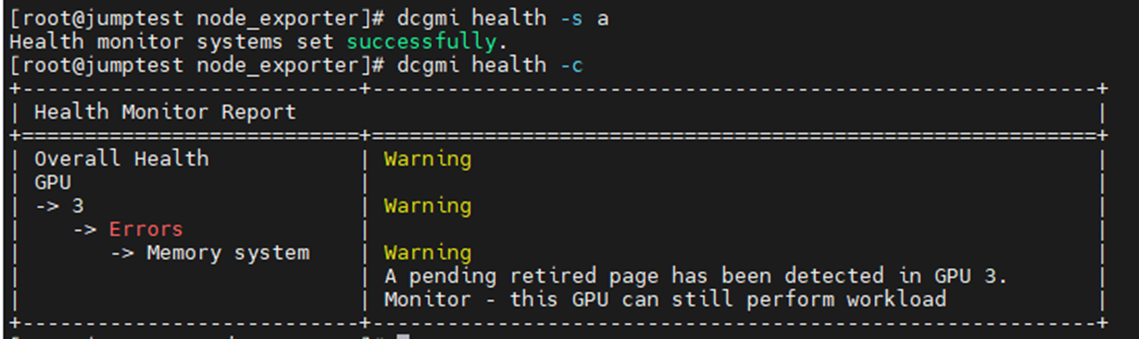
Em outro lugar, você pode ver quais são as falhas de memória na saída abaixo. Editado para mostrar apenas os itens relacionados à memória, podemos ver que a GPU encontrou 3.081 SBEs, com uma contagem agregada de vida útil de 6.161. Também vemos que a GPU tem uma página SBE anterior desativada com uma lista negra de páginas pendentes adicionais.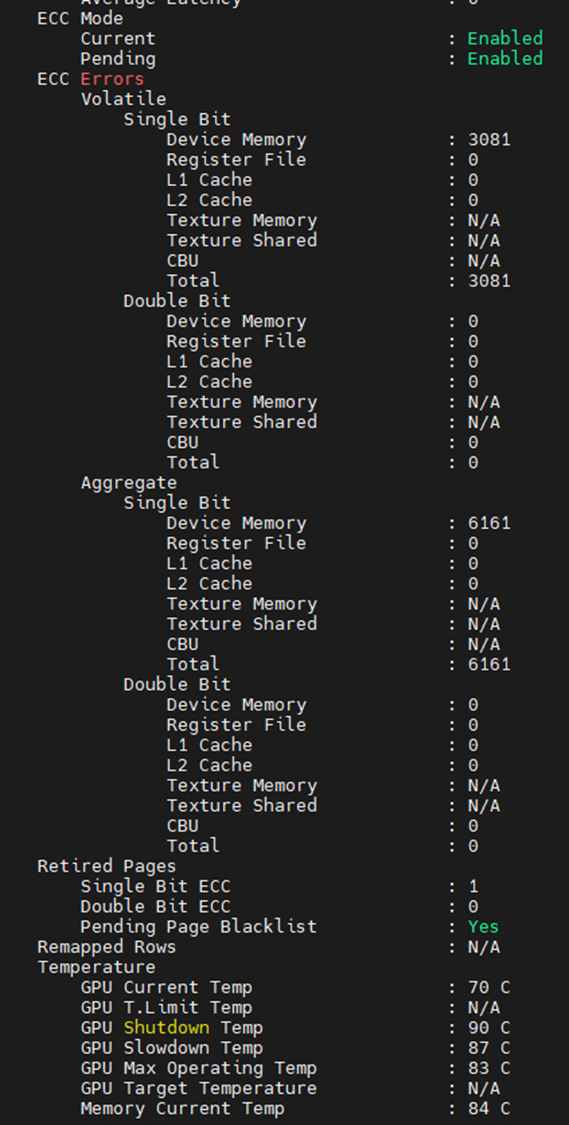
Caso você veja falhas de memória nas GPUs, o dispositivo em si deve ser redefinido. Isso é feito por meio da reinicialização de todo o sistema ou emissão da redefinição da GPU nvidia-smi em relação ao dispositivo.
Depois que o driver é descarregado, o endereço de memória da lista negra marcado é mapeado. Quando o driver é recarregado, a GPU recebe uma nova tabela de endereços com os endereços afetados bloqueados, semelhante ao PPR em CPUs Intel).
A falha na redefinição da GPU geralmente leva ao incremento de contadores voláteis e agregados. Isso ocorre porque a GPU ainda permite usar o endereço afetado, ou seja, cada vez que ela é atingida, aumenta os contadores.
Se você ainda suspeitar de falhas em uma ou mais GPUs, execute o NVIDIA fieldiags (diagnóstico 629) para um teste mais detalhado na GPU de destino.
**CERTIFIQUE-SE DE USAR O FIELDIAGS CORRETO E MAIS RECENTE PARA A GPU INSTALADA. ISSO É ESSENCIAL**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.