PowerEdge: NVIDIA DataCenter GPU Manager'ı (DCGM) yükleme ve tanılamayı çalıştırma
Summary: Linux'ta (RHEL/Ubuntu) NVIDIA DCGM (veri merkezi GPU yöneticisi) aracının nasıl kurulacağına ve tanılama uygulamasının nasıl çalıştırılacağına ve anlaşılacağına genel bakış.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Linux'ta DCGM nasıl kurulur:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMDCGM 3.3 Kullanıcı ve Kurulum Rehberi
En Son DCGM'yi
Yükleme Yazılımı indirip kullanarak, NVIDIA DCGM Lisansının hüküm ve koşullarına tam olarak uymayı kabul edersiniz.
NVIDIA Sürücü İndirmeleri sayfasından indirilebilen en yeni R450+ NVIDIA veri merkezi sürücüsünün kullanılması önerilir.
Önerilen yöntem olarak DCGM'yi doğrudan CUDA ağ depolarından yükleyin. Daha eski DCGM sürümleri de depolardan edinilebilir.
DCGM'nin Özellikleri:
- GPU davranışı izleme
- GPU yapılandırma yönetimi
- GPU politika gözetimi
- GPU sağlığı ve tanılamaları
- GPU muhasebe ve işlem istatistikleri
- NVSwitch yapılandırması ve izleme
Hızlı Başlangıç Talimatları:
Ubuntu LTS
CUDA ağ deposu meta verilerini, GPG anahtarını ayarlama Aşağıda gösterilen örnek, x86_64 da Ubuntu 20.04 içindir:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
DCGM'yi yükleyin.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat
CUDA ağ deposu meta verilerini, GPG anahtarını ayarlama Aşağıda gösterilen örnek, x86_64 işletim sisteminde RHEL 8 içindir:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
DCGM'yi yükleyin.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
DCGM nasıl çalıştırılır:
Datacenter GPU Manager (DCGM), müşterilerin GPU'ları işletim sistemi içinden test etmeleri için daha hızlı bir yoldur. Dört test seviyesi vardır. En derinlemesine sonuçlar için 4. seviye testi çalıştırın. Genellikle yaklaşık 1 saat 30 dakika sürer, ancak bu GPU türüne ve miktarına göre değişebilir. Bu araç, müşterinin testleri otomatik olarak çalışacak şekilde yapılandırabilmesini ve müşteriyi uyarmasını sağlayabilir. Bununla ilgili daha fazla bilgiyi bu bağlantıdan bulabilirsiniz. Her zaman en son sürümü kullanmanızı tavsiye ederiz, sürüm 3.3 en son yapıdır.
1. Örnek:
Komut: dcgmi diag -r 1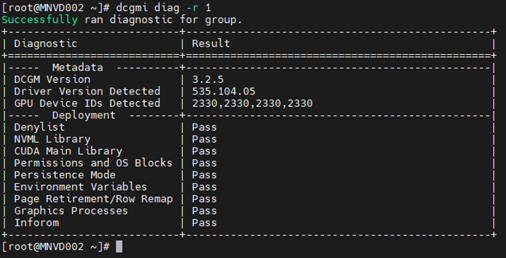
2. Örnek:
Komut: dcgmi diag -r 2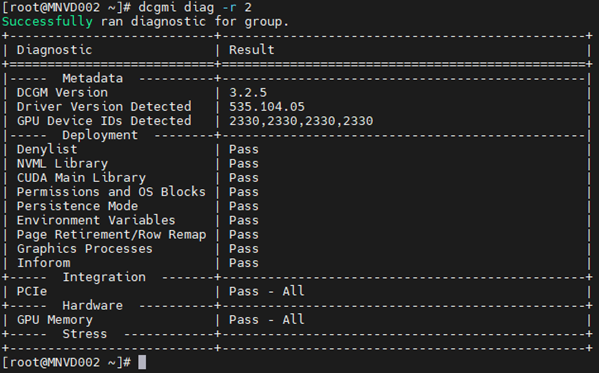
3. Örnek:
Komut: dcgm diag -r 3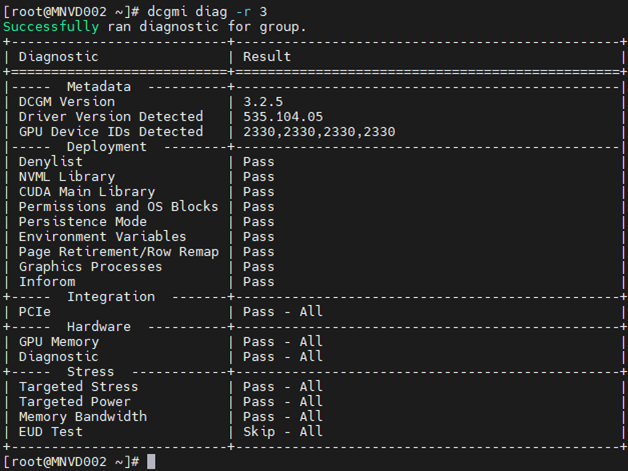
4. Örnek:
Komut: dcgm diag -r 4
Tanılama, niş yapıları, iş yükü özgüllüğü veya bunları algılamak için uzun çalışma sürelerine ihtiyaç duyulması nedeniyle bazı hataları gözden kaçırabilir.
Bir hata görürseniz hatanın kaynağını tam olarak anlamak için hatayı araştırın.
Çekerek başlayın nvidia-bug-report.sh komutunu (yalnızca Linux işletim sisteminde yerel, Windows yok) çalıştırın ve çıktı dosyasını inceleyin.
Bellek uyarı hatası örnekleri:
Aşağıdaki örnekte, sunucudaki tüm takılı GPU'lar kontrol edilerek DCGM Sistem Durumu izleyicisinin etkinleştirilmesi ve başlatılması gösterilmiştir. GPU3'ün SBE'ler (tek bit hataları) ve etkilenen bellek adresini devre dışı bırakmak isteyen sürücü hakkında bir uyarı ürettiğini görebilirsiniz.
Komut: dcgmi health -s a (bu sağlık hizmetini başlatır ve "a" ona her şeyi izlemesini söyler)
Komut: dcgmi health -c (bu, keşfedilen tüm GPU'ları kontrol eder ve bunları raporlar)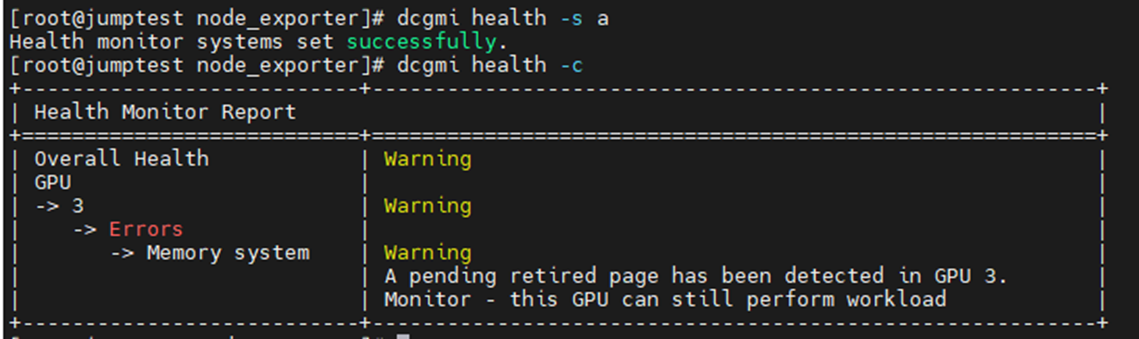
Bellek arızalarının ne olduğunu görebileceğiniz başka bir yer aşağıdaki çıktıdır. Yalnızca bellekle ilgili öğeleri gösterecek şekilde düzenlendiğinde, GPU'nun 3.081 SBE ile karşılaştığını ve yaşam boyu toplam sayının 6.161 olduğunu görebiliriz. Ayrıca GPU nun daha önce bir SBE kullanımdan kaldırılmış sayfası ve ek bir bekleyen sayfa kara listesi olduğunu görüyoruz.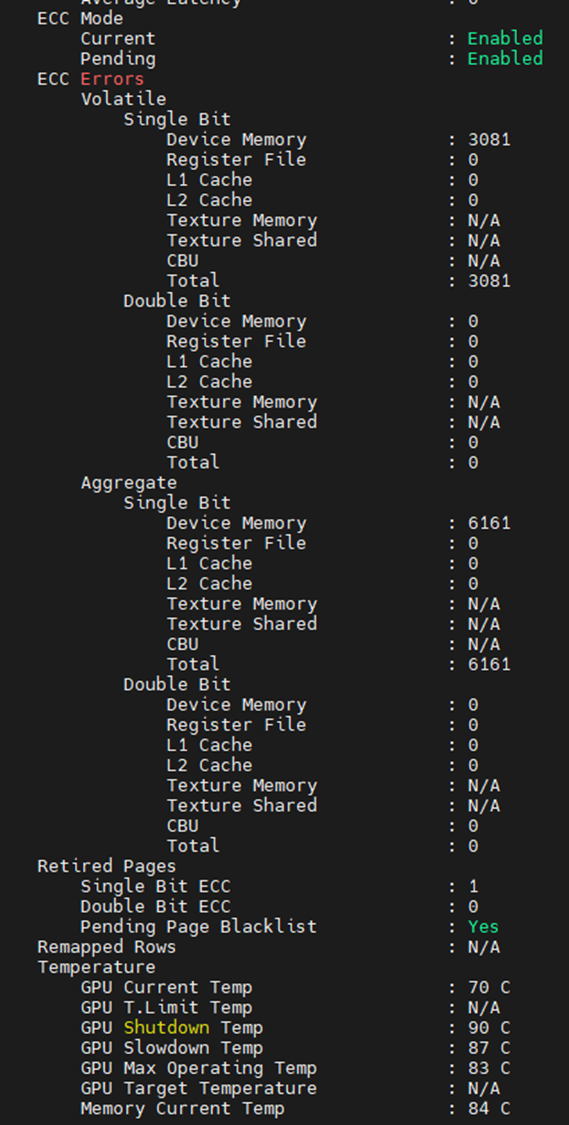
GPU'larda bellek hataları görmeniz durumunda, cihazın kendisinin sıfırlanması gerekir. Bu, tüm sistemin yeniden başlatılması veya aygıta karşı nvidia-smi GPU sıfırlaması yapılmasıyla gerçekleştirilir.
Sürücü boşaltıldıktan sonra, işaretli kara liste bellek adresi eşleştirilir. Sürücü yeniden yüklendiğinde GPU, Intel CPU'lardaki PPR'ye benzer şekilde, etkilenen adreslerin engellendiği yeni bir adres tablosu alır.
GPU'nun sıfırlanamaması genellikle geçici ve toplam sayaçlarda artışa neden olur. Bunun nedeni, GPU'nun etkilenen adresi kullanmaya devam etmesidir, bu nedenle her vurulduğunda sayaçlar artar.
Hala bir veya daha fazla GPU'da arıza olduğundan şüpheleniyorsanız hedeflenen GPU'da daha ayrıntılı bir test için NVIDIA fieldiags (629 tanılama) çalıştırın.
**TAKILAN GPU IÇIN EN YENI VE DOĞRU FIELDIAG'LERI KULLANDIĞINIZDAN EMIN OLUN, BU ÇOK ÖNEMLIDIR**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.