PowerEdge:NVIDIA DataCenter GPU Manager (DCGM) 安裝和如何執行診斷
Summary: 概觀說明如何在 Linux (RHEL/Ubuntu) 中安裝 NVIDIA 的 DCGM (資料中心 GPU 管理員) 工具,以及如何執行和瞭解診斷應用程式。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
如何在 Linux 中安裝 DCGM:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMDCGM 3.3 使用者和安裝指南
安裝最新的 DCGM
下載和使用本軟體,即表示您同意完全遵守 NVIDIA DCGM 授權的條款和條件。
建議使用最新的 R450+ NVIDIA 資料中心驅動程式,該驅動程式可從 NVIDIA 驅動程式下載頁面下載。
建議的方法是直接從 CUDA 網路儲存庫安裝 DCGM。亦可從存放庫取得較舊的 DCGM 版本。
DCGM 的特性:
- GPU 行為監控
- GPU 組態管理
- GPU 原則監督
- GPU 執行狀況與診斷
- GPU 記帳和處理統計資料
- NVSwitch 組態與監控
快速入門說明:
Ubuntu LTS
設定 CUDA 網路儲存庫中繼資料、GPG 金鑰 以下顯示的範例適用於 x86_64 上的 Ubuntu 20.04:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
安裝 DCGM。
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
紅帽
設定 CUDA 網路儲存庫中繼資料、GPG 金鑰 以下顯示的範例適用於 x86_64 上的 RHEL 8:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
安裝 DCGM。
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
如何執行 DCGM:
資料中心 GPU Manager (DCGM) 可讓客戶更快速地從作業系統內測試 GPU。有四個級別的測試。運行 4 級測試以獲得最深入的結果。這通常需要大約 1 小時 30 分鐘,但這可能因 GPU 類型和數量而異。此工具可讓客戶將測試設定為自動執行,並通知客戶。您可以從此 連結找到更多資訊。我們建議始終使用最新版本,版本 3.3 是最新版本。
範例 #1:
命令: dcgmi diag -r 1
範例 #2:
命令: dcgmi diag -r 2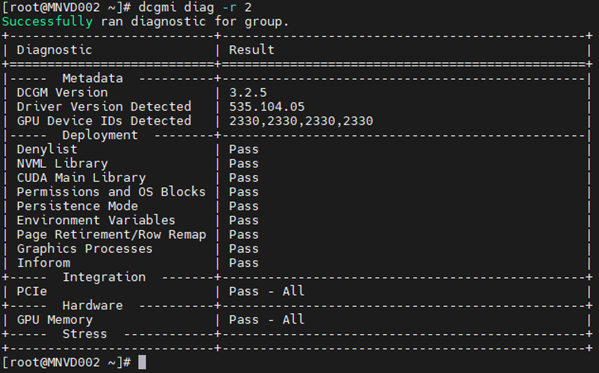
範例 #3:
命令: dcgm diag -r 3
範例 #4:
命令: dcgm diag -r 4
診斷程式可能會因為錯誤的特定性質、工作負荷特異性,或需要延長的執行時間來偵測錯誤,因此可能會遺漏某些錯誤。
如果發現錯誤,請對其進行調查以完全瞭解其性質。
首先拉出 nvidia-bug-report.sh 命令 (僅限 Linux 作業系統原生,無 Windows),並檢閱輸出檔案。
記憶體警示失敗的範例:
以下範例是啟用並啟動 DCGM 執行狀況監控器,隨後會檢查伺服器中所有已安裝的 GPU。您可以看到 GPU3 產生了有關 SBE(單位錯誤)和驅動程式想要淘汰受影響的記憶體位址的警告。
令: dcgmi health -s a (這將啟動健康服務,“a”告訴它監視一切)
令: dcgmi health -c (這會檢查所有探索到的 GPU,並針對這些 GPU 提出報告)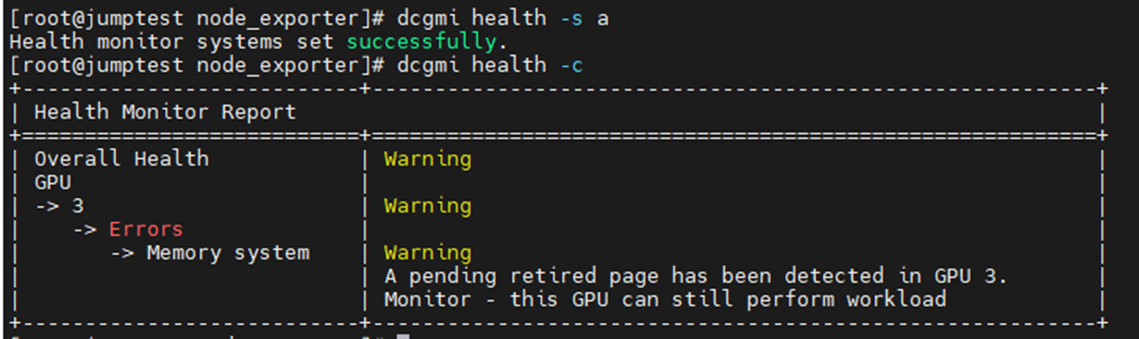
另一個地方,您可以從下面的輸出中看到記憶體故障是什麼。經編輯以僅顯示與記憶體相關的項目,我們可以看到 GPU 遇到 3,081 個 SBE,生命週期總計為 6,161。我們還看到 GPU 有一個以前的 SBE 已停用頁面,還有一個額外的待處理頁面黑名單。
萬一您在 GPU 上看到記憶體故障,則必須重設裝置本身。這是透過整個系統重新開機或針對裝置發出 nvidia-smi GPU 重設來完成。
卸載驅動程式后,將映射出標記的黑名單記憶體位址。當驅動程式重新載入時,GPU 會取得新的位址表格,其中受影響的位址會遭到封鎖,類似於 Intel CPU 上的 PPR)。
無法重設 GPU 通常會導致揮發性和聚合計數器增加。這是因為 GPU 仍可使用受影響的位址,因此每次按下該位址時,都會增加一次。
如果您仍懷疑一或多個 GPU 有故障,請執行 NVIDIA fieldiags (629 診斷程式),以對目標 GPU 進行更深入的測試。
**請務必為安裝的 GPU 使用最新且正確的欄位,這一點非常重要**。
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.