PowerEdge: Встановлення NVIDIA DataCenter GPU Manager (DCGM) і як провести діагностику
Summary: Огляд того, як встановити інструмент DCGM (менеджер графічних процесорів центру обробки даних) від NVIDIA в Linux (RHEL/Ubuntu), а також як запустити та зрозуміти програму діагностики.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Як встановити DCGM в Linux:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMDCGM 3.3 Посібник користувача та встановлення
Встановлення останньої версії DCGM
Завантажуючи та використовуючи програмне забезпечення, ви погоджуєтеся повністю дотримуватися умов та положень ліцензії NVIDIA DCGM.
Рекомендується використовувати найновіший драйвер датацентру R450+ NVIDIA, який можна завантажити зі сторінки завантаження драйверів NVIDIA.
Як рекомендований метод, встановіть DCGM безпосередньо з мережевих репозиторіїв CUDA. Старіші релізи DCGM також доступні з репозиторіїв.
Особливості DCGM:
- Моніторинг поведінки графічного процесора
- Керування конфігурацією графічного процесора
- Нагляд за політикою GPU
- Справність та діагностика графічного процесора
- Облік GPU та статистика процесів
- Конфігурація та моніторинг NVSwitch
Інструкції QuickStart:
Ubuntu LTS
Налаштуйте метадані мережевого репозиторію CUDA, ключ GPG Приклад, показаний нижче, призначений для Ubuntu 20.04 на x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Встановіть DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Червоний капелюх
Налаштуйте метадані мережевого репозиторію CUDA, ключ GPG Приклад, показаний нижче, призначений для RHEL 8 на x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Встановіть DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Як запустити DCGM:
Datacenter GPU Manager (DCGM) – це швидший спосіб для клієнтів тестувати графічні процесори з ОС. Існує чотири рівні тестів. Проведіть тест 4 рівня, щоб отримати найглибші результати. Зазвичай це займає близько 1 години 30 хвилин, але це може відрізнятися залежно від типу та кількості графічного процесора. Інструмент має можливість для клієнта налаштувати тести для автоматичного виконання та оповіщення клієнта. Більше про це можна дізнатися за цим посиланням. Ми б радили завжди використовувати останню версію, версія 3.3 є останньою збіркою.
Приклад #1:
Команда: dcgmi diag -r 1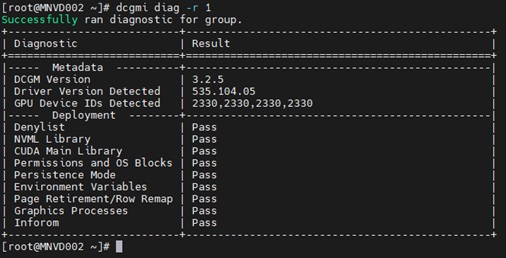
Приклад #2:
Команда: dcgmi diag -r 2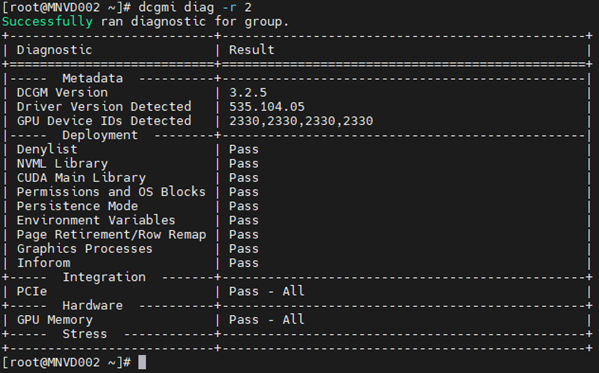
Приклад #3:
Команда: dcgm diag -r 3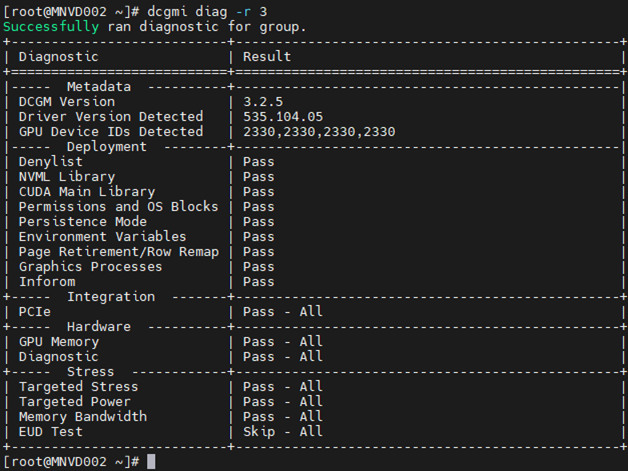
Приклад #4:
Команда: dcgm diag -r 4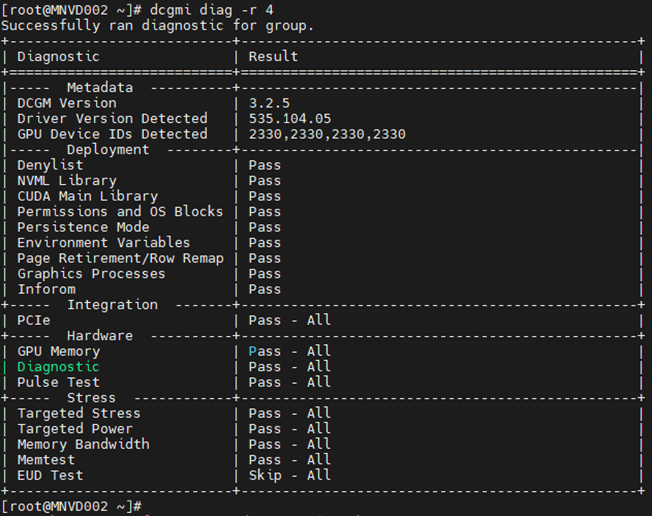
Діагностика може пропустити деякі помилки через їх нішевий характер, специфіку робочого навантаження або необхідність подовженого часу роботи для їх виявлення.
Якщо ви бачите помилку, дослідіть її, щоб повністю зрозуміти її природу.
Почніть з витягування nvidia-bug-report.sh (рідна лише для ОС Linux, без Windows) і перегляньте вихідний файл.
Приклади сповіщень про збій у пам'яті:
У наведеному нижче прикладі було увімкнення та запуск монітора DCGM Health з подальшою перевіркою всіх встановлених графічних процесорів на сервері. Ви можете бачити, що GPU3 видавав попередження про SBE (однобітові помилки) і про те, що драйвер хоче видалити проблемну адресу пам'яті.
Команда: dcgmi health -s a (Це запускає службу охорони здоров'я і «А» каже їй дивитися все підряд)
Команда: dcgmi health -c (при цьому перевіряються всі виявлені графічні процесори та звітує про них)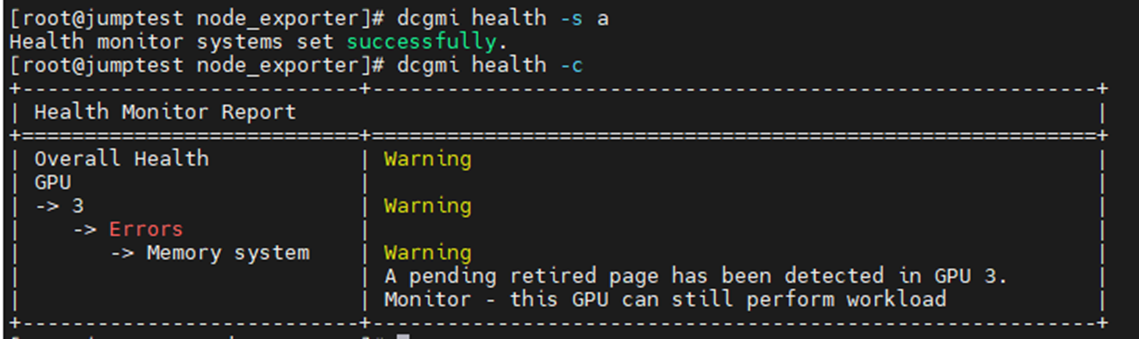
В іншому місці ви можете побачити, в чому полягають несправності пам'яті, з виводу нижче. Відредаговано, щоб показати лише елементи, пов'язані з пам'яттю, ми можемо побачити, що графічний процесор зіткнувся з 3 081 SBE із загальною кількістю за весь час життя 6 161. Ми також бачимо, що графічний процесор має одну попередню сторінку SBE, що вибула з експлуатації, з додатковим чорним списком сторінок, що очікують на розгляд.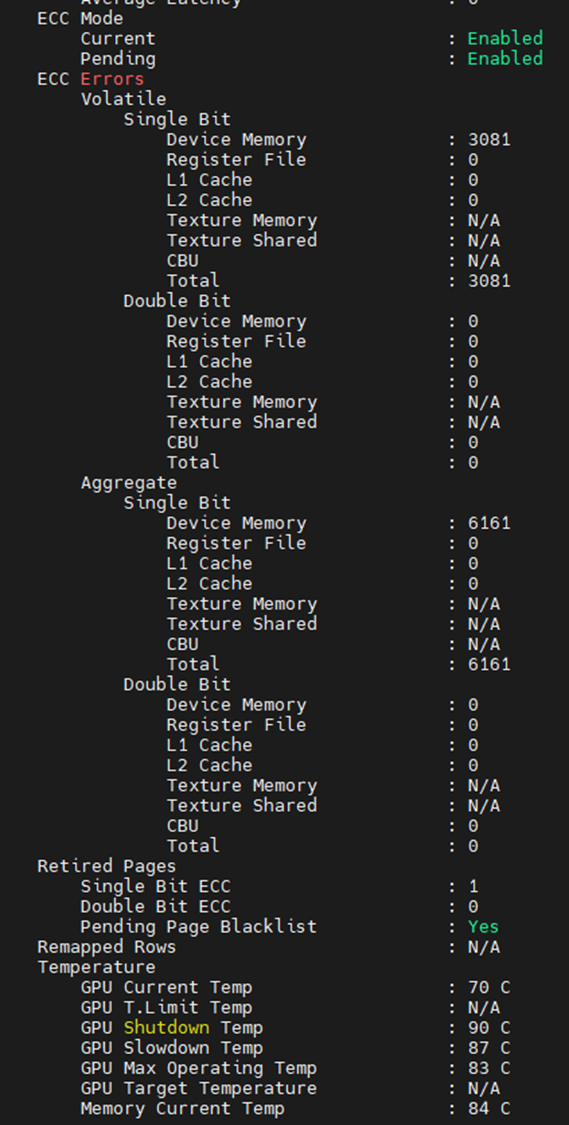
У випадку, якщо ви бачите несправності пам'яті на графічних процесорах, сам пристрій має бути скинуто. Це досягається перезавантаженням всієї системи або скиданням графічного процесора nvidia-smi проти пристрою.
Після того, як драйвер вивантажується, позначається адреса пам'яті чорного списку. Коли драйвер перезавантажується, графічний процесор отримує нову таблицю адрес із заблокованими адресами, що зазнали впливу, подібно до PPR на процесорах Intel).
Відмова від скидання налаштувань графічного процесора часто призводить до збільшення нестабільних і агрегатних лічильників. Це пов'язано з тим, що графічний процесор все ще дозволяє використовувати цю уражену адресу, тому кожного разу, коли вона потрапляє, лічильники збільшуються.
Якщо ви все ще підозрюєте несправності в одному або кількох графічних процесорах, запустіть NVIDIA Fieldiags (діагностика 629) для більш глибокого тестування цільового графічного процесора.
**ПЕРЕКОНАЙТЕСЯ, ЩО ВИ ВИКОРИСТОВУЄТЕ НАЙНОВІШІ ТА ПРАВИЛЬНІ ПОЛЯ ДЛЯ ВСТАНОВЛЕНОГО ГРАФІЧНОГО ПРОЦЕСОРА, ЦЕ КРИТИЧНО ВАЖЛИВО**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.