PowerEdge : Installation de NVIDIA DataCenter GPU Manager (DCGM) et exécution des diagnostics
Summary: Présentation de l’installation de l’outil DCGM (Datacenter GPU Manager) de NVIDIA sous Linux (RHEL/Ubuntu), de l’exécution et de la compréhension de l’application de diagnostic.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Comment installer DCGM sous Linux :
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMGuide de l’utilisateur et d’installation de DCGM 3.3
Installation de la dernière version de DCGM
En téléchargeant et en utilisant le logiciel, vous acceptez de vous conformer pleinement aux termes et conditions de la licence NVIDIA DCGM.
Il est recommandé d’utiliser la dernière version du pilote NVIDIA Datacenter R450+ qui peut être téléchargée à partir de la page NVIDIA Driver Downloads.
La méthode recommandée consiste à installer DCGM directement à partir des référentiels réseau CUDA. Les anciennes versions de DCGM sont également disponibles dans les dépôts.
Caractéristiques de DCGM :
- Surveillance du comportement du processeur graphique
- Gestion de la configuration du processeur graphique
- Supervision de la stratégie de processeur graphique
- Intégrité et diagnostics du processeur graphique
- Statistiques de processus et de comptabilité du processeur graphique
- Configuration et surveillance de NVSwitch
Instructions de démarrage rapide :
Ubuntu LTS
Configuration des métadonnées du référentiel réseau CUDA, clé GPG L’exemple ci-dessous concerne Ubuntu 20.04 sur x86_64 :
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Installez DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Chapeau
Configuration des métadonnées du référentiel réseau CUDA, clé GPG L’exemple ci-dessous concerne RHEL 8 sur x86_64 :
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Installez DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Comment exécuter DCGM :
DCGM (Datacenter GPU Manager) est un moyen plus rapide pour les clients de tester les GPU à partir du système d’exploitation. Il existe quatre niveaux de tests. Exécutez le test de niveau 4 pour obtenir les résultats les plus approfondis. Cela prend généralement environ 1 h 30 minutes, mais cela peut varier en fonction du type et de la quantité de GPU. L’outil permet au client de configurer les tests pour qu’ils s’exécutent automatiquement et d’alerter le client. Vous trouverez plus d’informations à ce sujet en cliquant sur ce lien. Nous vous conseillons de toujours utiliser la dernière version, la version 3.3 est la dernière version.
Exemple 1 :
Commande : dcgmi diag -r 1
Exemple 2 :
Commande : dcgmi diag -r 2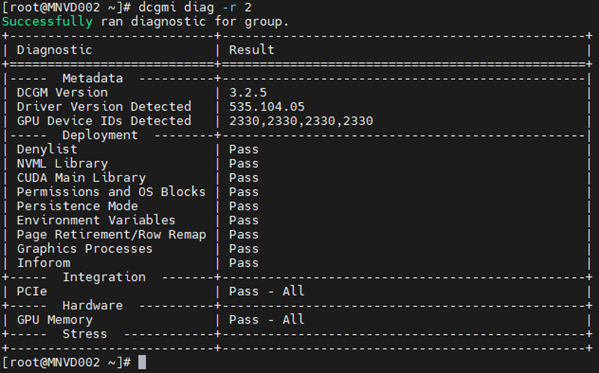
Exemple 3 :
Commande : dcgm diag -r 3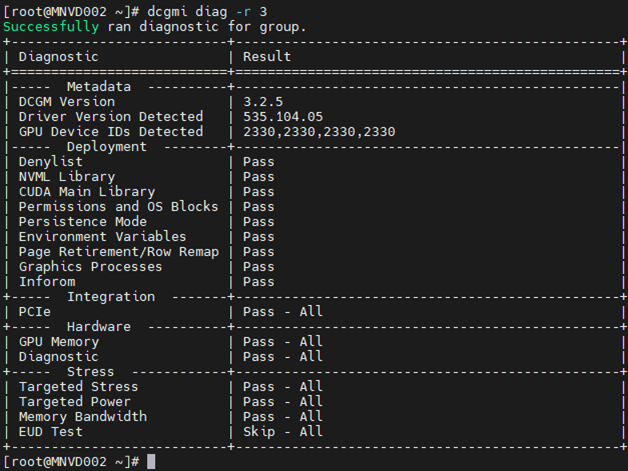
Exemple 4 :
Commande : dcgm diag -r 4
Le diagnostic peut passer à côté de certaines erreurs en raison de leur nature de niche, de la spécificité des charges applicatives ou de la nécessité d’étendre les temps d’exécution pour les détecter.
Si vous voyez une erreur, examinez-la pour bien comprendre la nature de celle-ci.
Commencez par tirer sur le nvidia-bug-report.sh (native du système d’exploitation Linux uniquement, pas de Windows) et vérifiez le fichier de sortie.
Exemples d’échec d’alerte mémoire :
L’exemple ci-dessous concernait l’activation et le démarrage du moniteur d’intégrité DCGM, puis une vérification ultérieure de tous les processeurs graphiques installés sur le serveur était en cours. Vous pouvez voir que GPU3 a généré un avertissement concernant les erreurs d’un seul bit (SBE) et le pilote souhaitant retirer l’adresse mémoire affectée.
Commander: dcgmi health -s a (Cela démarre le service de santé et le « A » lui dit de tout surveiller)
Commander: dcgmi health -c (ce service vérifie tous les processeurs graphiques détectés et en fait rapport)
Un autre endroit où vous pouvez voir quelles sont les pannes de mémoire à partir de la sortie ci-dessous. Modifié pour afficher uniquement les éléments liés à la mémoire, nous pouvons voir que le processeur graphique a rencontré 3 081 SBE, avec un nombre cumulé de vie de 6 161. Nous voyons également que le processeur graphique dispose d’une page SBE précédemment retirée avec une liste noire de pages en attente supplémentaire.
Si vous constatez des pannes de mémoire sur les processeurs graphiques, l’appareil lui-même doit être réinitialisé. Ceci est accompli par un redémarrage complet du système ou par l’émission d’une réinitialisation du processeur graphique nvidia-smi sur l’appareil.
Une fois le pilote déchargé, l’adresse mémoire marquée sur liste noire est mappée. Lorsque le pilote se recharge, le processeur graphique obtient une nouvelle table d’adresses avec les adresses affectées bloquées, similaire à PPR sur les processeurs Intel).
L’échec de la réinitialisation du processeur graphique entraîne souvent une incrémentation des compteurs volatiles et agrégés. Cela est dû au fait que le GPU permet toujours d’utiliser cette adresse affectée, donc chaque fois qu’elle est atteinte, les compteurs augmentent.
Si vous soupçonnez toujours des défaillances sur un ou plusieurs processeurs graphiques, exécutez les diagnostics NVIDIA (629 diagnostics) pour effectuer un test plus approfondi sur le processeur graphique cible.
**ASSUREZ-VOUS D’UTILISER LES FIELDIAG LES PLUS RÉCENTS ET CORRECTS POUR LE PROCESSEUR GRAPHIQUE INSTALLÉ, CELA EST ESSENTIEL**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.