PowerEdge: Installatie van NVIDIA DataCenter GPU Manager (DCGM) en het uitvoeren van diagnostiek
Summary: Overzicht van het installeren van de DCGM-tool (datacenter GPU manager) van NVIDIA in Linux (RHEL/Ubuntu) en het uitvoeren en begrijpen van de diagnostische applicatie.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Hoe DCGM in Linux te installeren:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMDCGM 3.3 gebruikers- en installatiehandleiding
De nieuwste DCGM
installeren Door de software te downloaden en te gebruiken, gaat u ermee akkoord dat u volledig voldoet aan de voorwaarden van de NVIDIA DCGM-licentie.
Het wordt aanbevolen om de nieuwste R450+ NVIDIA datacenterdriver te gebruiken die kan worden gedownload van de pagina NVIDIA-driverdownloads.
Als aanbevolen methode installeert u DCGM rechtstreeks vanaf de CUDA-netwerkrepo's. Oudere DCGM-releases zijn ook beschikbaar in de repo's.
Kenmerken van DCGM:
- Controle van GPU-gedrag
- GPU-configuratiebeheer
- Toezicht op GPU-beleid
- GPU-status en diagnostiek
- GPU-boekhouding en processtatistieken
- NVSwitch-configuratie en -bewaking
Snelstartinstructies:
Ubuntu LTS
De metadata van de CUDA-netwerkrepository instellen, GPG-sleutel Het onderstaande voorbeeld is voor Ubuntu 20.04 op x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Installeer DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat
De metadata van de CUDA-netwerkrepository instellen, GPG-sleutel Het onderstaande voorbeeld is voor RHEL 8 op x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Installeer DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
DCGM uitvoeren:
Datacenter GPU Manager (DCGM) is een snellere manier voor klanten om GPU's te testen vanuit het besturingssysteem. Er zijn vier testniveaus. Voer de test van niveau 4 uit voor de meest diepgaande resultaten. Het duurt meestal ongeveer 1 uur en 30 minuten, maar dit kan variëren afhankelijk van het type en de hoeveelheid GPU. De tool biedt de klant de mogelijkheid om de tests zo te configureren dat deze automatisch worden uitgevoerd en de klant wordt gewaarschuwd. Meer daarover vind je via deze link. Wij adviseren om altijd de laatste versie te gebruiken, versie 3.3 is de laatste versie.
Voorbeeld 1:
Opdracht: dcgmi diag -r 1
Voorbeeld 2:
Opdracht: dcgmi diag -r 2
Voorbeeld 3:
Opdracht: dcgm diag -r 3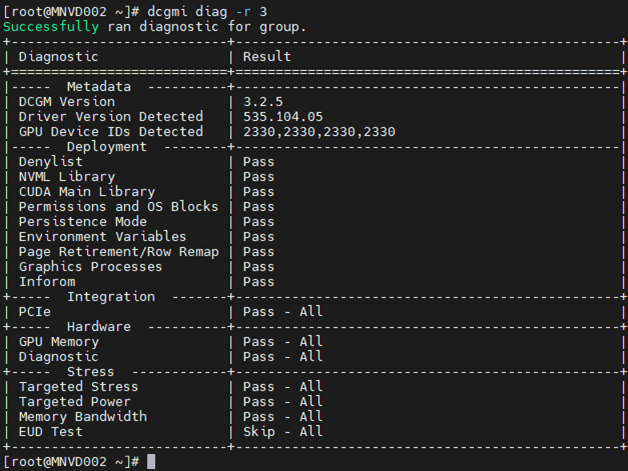
Voorbeeld 4:
Opdracht: dcgm diag -r 4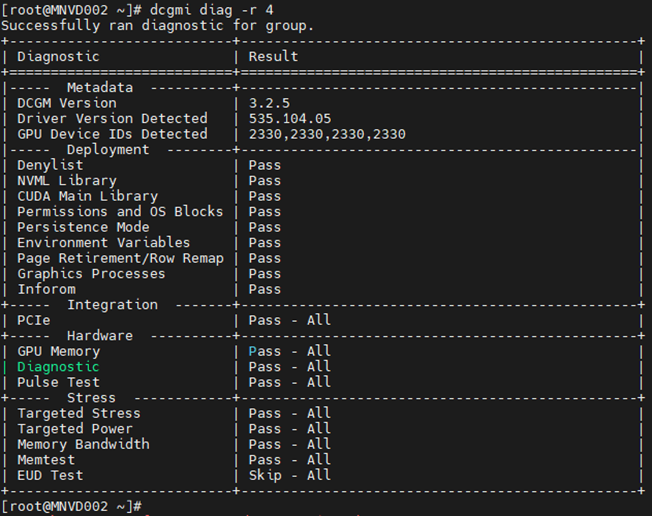
De diagnose kan enkele fouten over het hoofd zien vanwege hun niche-aard, workloadspecificiteit of de noodzaak van langere runtimes om ze te detecteren.
Mocht u een fout zien, onderzoek deze dan om de aard ervan volledig te begrijpen.
Begin met het trekken van de nvidia-bug-report.sh command (alleen native voor Linux, geen Windows) en controleer het uitvoerbestand.
Voorbeelden van een fout bij een geheugenmelding:
Het onderstaande voorbeeld was het inschakelen en starten van de DCGM Health Monitor met een daaropvolgende controle van alle geïnstalleerde GPU's in de server. U ziet dat GPU3 een waarschuwing heeft gegenereerd over SBE's (single bit errors) en de driver die het getroffen geheugenadres wil opheffen.
Bevelen: dcgmi health -s a (Dit start de gezondheidsdienst en de "A" vertelt het om alles in de gaten te houden)
Bevelen: dcgmi health -c (deze controleert alle ontdekte GPU's en rapporteert erover)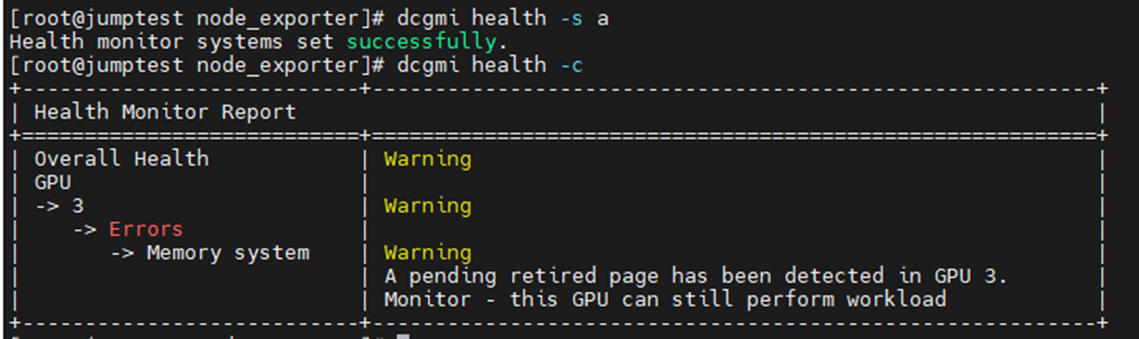
Een andere plaats waar u kunt zien wat de geheugenfouten zijn uit de onderstaande uitvoer. Bewerkt om alleen de geheugengerelateerde items weer te geven, kunnen we zien dat de GPU 3.081 SBE's tegenkwam, met een totaal van 6.161. We zien ook dat de GPU één eerdere SBE-ingetrokken pagina heeft met een extra zwarte lijst voor in behandeling zijnde pagina's.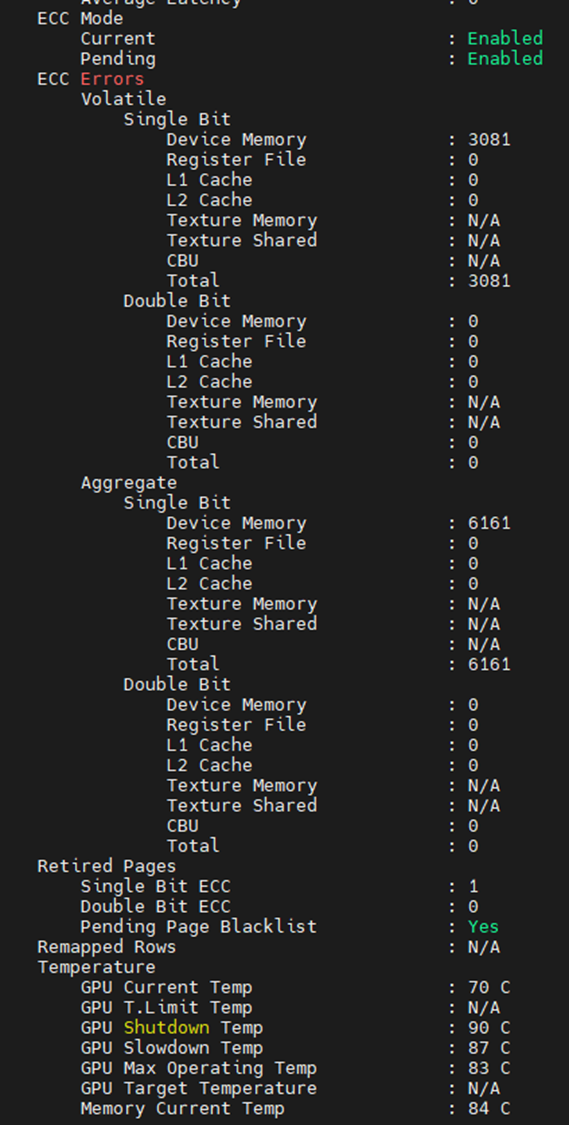
In het geval dat u geheugenfouten op GPU's ziet, moet het apparaat zelf worden gereset. Dit wordt gedaan door het hele systeem opnieuw op te starten of door de nvidia-smi GPU-reset op het apparaat uit te voeren.
Nadat de driver is gelost, wordt het gemarkeerde blacklist-geheugenadres toegewezen. Wanneer de driver opnieuw wordt geladen, krijgt de GPU een nieuwe adrestabel met de getroffen adressen geblokkeerd, vergelijkbaar met PPR op Intel CPU's).
Het niet resetten van de GPU leidt vaak tot een toename van vluchtige en geaggregeerde tellers. Dit komt doordat de GPU nog steeds toestaat om dat getroffen adres te gebruiken, dus elke keer dat het wordt geraakt, neemt de teller toe.
Als u nog steeds storingen in een of meer GPU's vermoedt, voert u de NVIDIA-fieldiags (629 diagnostics) uit voor een meer diepgaande test op de doel-GPU.
**ZORG ERVOOR DAT U DE NIEUWSTE EN JUISTE VELDEN GEBRUIKT VOOR DE GEÏNSTALLEERDE GPU, DIT IS VAN CRUCIAAL BELANG**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.