PowerEdge. Установка NVIDIA DataCenter GPU Manager (DCGM) и запуск диагностики
Summary: Обзор установки инструмента NVIDIA DCGM (Datacenter GPU Manager) в Linux (RHEL/Ubuntu), а также о том, как запустить и изучить приложение диагностики.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Как установить DCGM в Linux:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMРуководство пользователя и установки DCGM 3.3
Установка последней версии DCGM
Загружая и используя программное обеспечение, вы соглашаетесь полностью соблюдать условия и положения лицензии NVIDIA DCGM.
Рекомендуется использовать последнюю версию драйвера NVIDIA для центра обработки данных R450+, которую можно скачать со страницы скачиваемых драйверов NVIDIA.
Рекомендуется установить DCGM непосредственно из сетевых репозиториев CUDA. Более ранние версии DCGM также доступны в репозиториях.
Особенности DCGM:
- Мониторинг поведения графического процессора
- Управление конфигурацией графического процессора
- Надзор за политиками графических процессоров
- Работоспособность и диагностика графического процессора
- Учет GPU и статистика процессов
- Настройка и мониторинг NVSwitch
Краткие инструкции по началу работы.
Ubuntu LTS
Настройка метаданных сетевого репозитория CUDA, ключа GPG Приведенный ниже пример относится к Ubuntu 20.04 в x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Установите DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat
Настройка метаданных сетевого репозитория CUDA, ключа GPG Ниже приведен пример для RHEL 8 на x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Установите DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Как запустить DCGM:
Datacenter GPU Manager (DCGM) позволяет заказчикам быстрее тестировать графические процессоры в ОС. Существует четыре уровня тестов. Для получения более подробных результатов выполните тест уровня 4. Обычно это занимает около 1 часа 30 минут, но это время зависит от типа и количества графических процессоров. Это средство позволяет заказчику настроить автоматический запуск тестов и оповещение заказчика. Подробнее об этом можно узнать по этой ссылке. Мы бы посоветовали всегда использовать последнюю версию, версия 3.3 является последней сборкой.
Пример 1
Команда. dcgmi diag -r 1
Пример 2
Команда. dcgmi diag -r 2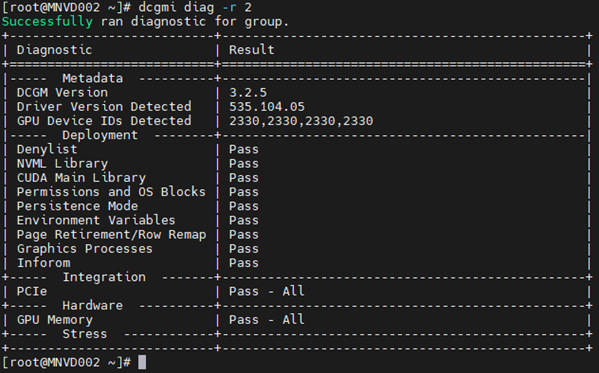
Пример 3
Команда. dcgm diag -r 3
Пример 4
Команда. dcgm diag -r 4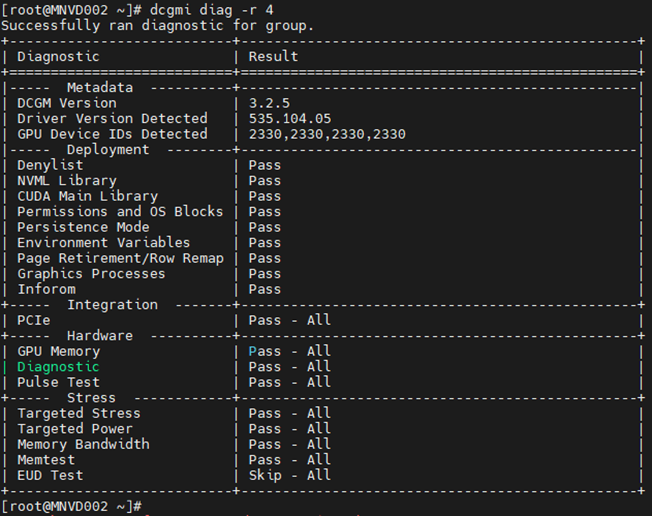
Диагностика может пропустить некоторые ошибки из-за их нишевого характера, специфики рабочих нагрузок или необходимости увеличения времени работы для их обнаружения.
Если вы заметили ошибку, исследуйте ее, чтобы полностью понять ее природу.
Начните с того, что вытащите nvidia-bug-report.sh (только для ОС Linux, без Windows) и просмотрите выходной файл.
Примеры сбоев оповещений о памяти:
Ниже показан пример включения и запуска DCGM Health Monitor с последующей проверкой всех установленных на сервере графических процессоров. Вы можете видеть, что графический процессор 3 выдал предупреждение о SBE (однобитовых ошибках) и о том, что драйвер хочет удалить затронутый адрес памяти.
Команда: dcgmi health -s a (Это запускает службу здравоохранения, и «А» говорит ей смотреть все)
Команда: dcgmi health -c (при этом проверяются все обнаруженные графические процессоры и создается отчет о них)
В выводе ниже также можно увидеть ошибки памяти. Отредактировав так, чтобы показать только элементы, связанные с памятью, мы видим, что графический процессор обнаружил 3081 SBE, а общее количество жизней составляет 6161. Мы также видим, что графический процессор имеет одну предыдущую страницу, выведенную из эксплуатации SBE, с дополнительной ожидающей страницей в черном списке.
Если вы видите неисправности памяти на графических процессорах, необходимо выполнить сброс самого устройства. Для этого требуется перезагрузка всей системы или сброс графического процессора nvidia-smi для устройства.
После выгрузки драйвера отмечается адрес памяти, занесенный в черный список. При перезагрузке драйвера графический процессор получает новую таблицу адресов с заблокированными затронутыми адресами (аналогично PPR на ЦП Intel).
Невыполнение сброса графического процессора часто приводит к увеличению счетчиков энергозависимых и агрегированных данных. Это связано с тем, что графический процессор по-прежнему позволяет использовать этот затронутый адрес, поэтому при каждом попадании счетчики увеличиваются.
Если вы по-прежнему подозреваете неисправность одного или нескольких графических процессоров, запустите NVIDIA fieldiags (диагностика 629) для более углубленного тестирования целевого графического процессора.
**УБЕДИТЕСЬ, ЧТО ВЫ ИСПОЛЬЗУЕТЕ ПОСЛЕДНИЕ И ПРАВИЛЬНЫЕ FIELDIAG ДЛЯ УСТАНОВЛЕННОГО ГРАФИЧЕСКОГО ПРОЦЕССОРА, ЭТО ОЧЕНЬ ВАЖНО**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.