PowerEdge: Installation av NVIDIA DataCenter GPU Manager (DCGM) och hur du kör diagnostik
Summary: Översikt över hur du installerar NVIDIA:s DCGM-verktyg (datacenter GPU manager) i Linux (RHEL/Ubuntu) och hur du kör och förstår diagnostikprogrammet.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Så här installerar du DCGM i Linux:
https://developer.nvidia.com/dcgm#Downloads
https://github.com/NVIDIA/DCGMAnvändar- och installationsmanual för DCGM 3.3
Installera den senaste DCGM:n
Genom att ladda ner och använda programvaran samtycker du till att till fullo följa villkoren i NVIDIA DCGM-licensen.
Vi rekommenderar att du använder den senaste R450+ NVIDIA-datacenterdrivrutinen som kan laddas ner från sidan Nedladdningar av NVIDIA-drivrutiner.
Som rekommenderad metod installerar du DCGM direkt från CUDA-nätverkslagringsplatsen. Äldre DCGM-versioner är också tillgängliga från lagringsplatserna.
Funktioner hos DCGM:
- Övervakning av GPU-beteende
- Konfigurationshantering för GPU
- Tillsyn av GPU-policyn
- GPU-hälsa och diagnostik
- GPU-redovisning och processstatistik
- NVSwitch konfiguration och övervakning
Instruktioner för snabbstart:
Ubuntu LTS
Konfigurera metadata för CUDA-nätverkslagringsplatsen, GPG-nyckel Exemplet nedan är för Ubuntu 20.04 på x86_64:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb $ sudo dpkg -i cuda-keyring_1.0-1_all.deb $ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /“
Installera DCGM.
$ sudo apt-get update && sudo apt-get install -y datacenter-gpu-manager
Red Hat (röd hatt)
Konfigurera metadata för CUDA-nätverkslagringsplatsen, GPG-nyckel Exemplet nedan är för RHEL 8 på x86_64:
*Pro-Tip for RHEL 9 repo simply replace the 8 below with 9 in the URL string* $ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
Installera DCGM.
$ sudo dnf clean expire-cache \ && sudo dnf install -y datacenter-gpu-manager Set up the DCGM service $ sudo systemctl --now enable nvidia-dcgm.
Så här kör du DCGM:
Datacenter GPU Manager (DCGM) är ett snabbare sätt för kunder att testa GPU:er inifrån operativsystemet. Det finns fyra testnivåer. Kör nivå 4-testet för de mest djupgående resultaten. Det tar vanligtvis cirka 1 timme och 30 minuter, men det kan variera beroende på GPU-typ och kvantitet. Verktyget gör det möjligt för kunden att konfigurera testerna så att de körs automatiskt och varna kunden. Du kan hitta mer om det från den här länken. Vi rekommenderar att du alltid använder den senaste versionen, version 3.3 är den senaste versionen.
Exempel 1:
Kommando: dcgmi diag -r 1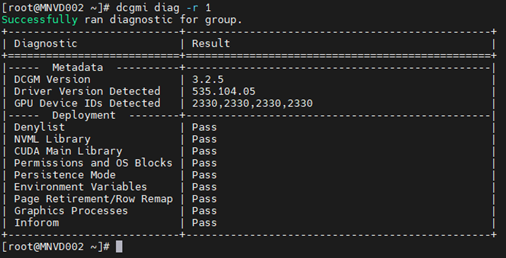
Exempel 2:
Kommando: dcgmi diag -r 2
Exempel 3:
Kommando: dcgm diag -r 3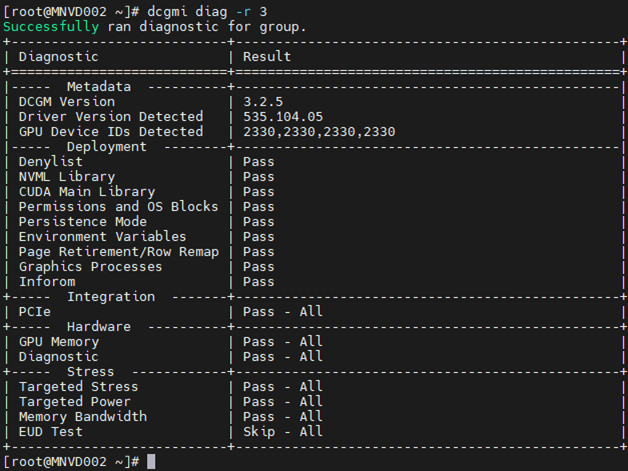
Exempel 4:
Kommando: dcgm diag -r 4
Diagnostiken kan missa vissa fel på grund av deras nischkaraktär, arbetsbelastningsspecificitet eller behovet av längre körtider för att identifiera dem.
Om du ser ett fel bör du undersöka det för att förstå vad det beror på.
Börja med att dra i nvidia-bug-report.sh (endast inbyggt i Linux OS, inga Windows) och granska utdatafilen.
Exempel på minnesavisering om fel:
I exemplet nedan aktiverar och startar DCGM-hälsoövervakaren med en efterföljande kontroll av alla installerade GPU:er på servern. Du kan se att GPU3 skapade en varning om SBE:er (enkelbitsfel) och att drivrutinen vill dra tillbaka den berörda minnesadressen.
Befallning: dcgmi health -s a (detta startar sjukvården och "A" säger åt den att titta på allt)
Befallning: dcgmi health -c (detta kontrollerar alla upptäckta GPU:er och rapporterar tillbaka om dem)
En annan plats där du kan se vad minnesfelen är från utgången nedan. Redigerad för att endast visa de minnesrelaterade objekten kan vi se att GPU:n påträffade 3 081 SBE:er, med ett sammantaget livstidsantal på 6 161. Vi ser också att GPU:n har en tidigare tillbakadragen SBE-sida med ytterligare en svartlista för väntande sidor.
Om du ser minnesfel på GPU:er måste själva enheten återställas. Detta åstadkoms genom en omstart av hela systemet eller genom att nvidia-smi GPU-återställning utfärdas mot enheten.
När drivrutinen har tagits bort mappas den markerade svartlistade minnesadressen ut. När drivrutinen läses in igen får GPU:n en ny adresstabell med de berörda adresserna blockerade, ungefär som PPR på Intel-processorer).
Om GPU:n inte återställs leder det ofta till en ökning av flyktiga och aggregerade räknare. Detta beror på att GPU:n fortfarande tillåter att den påverkade adressen används, så varje gång den träffas ökar räknarna.
Om du fortfarande misstänker fel i en eller flera GPU:er kör du NVIDIA-fälttester (629 diagnostics) för ett mer djupgående test på målgrafikprocessorn.
**SE TILL ATT DU ANVÄNDER DE SENASTE OCH KORREKTA FÄLTEN FÖR DEN INSTALLERADE GPU:N. DETTA ÄR KRITISKT**.
Affected Products
C Series, Rack Servers, Tower Servers, XE Servers, PowerEdge XE8545, PowerEdge XE8640Article Properties
Article Number: 000219485
Article Type: How To
Last Modified: 27 May 2025
Version: 5
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.