PowerScale, Isilon OneFS: Testowanie wydajności HBase w Isilon
Summary: W tym artykule przedstawiono testy wydajności klastra Isilon X410 przy użyciu pakietu Yahoo Cloud Serving Benchmarking (YCSB) i Cloudera Data Hub (CDH) 5.10.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Niewymagany
Cause
Niewymagany
Resolution
UWAGA: Ten temat jest częścią centrum informacji Korzystanie z Hadoop w OneFS.
Wprowadzenie
Przeprowadzono serię testów wydajności klastra Isilon X410 przy użyciu pakietu YCSB Benchmarking Suite i CDH 5.10.
Środowisko testowe laboratorium zostało skonfigurowane z pięcioma węzłami Isilon x410 z systemem OneFS w wersji 8.0.0.4 lub nowszej 8.0.1.1. Przeprowadzono testy porównawcze przesyłania strumieniowego dużych bloków systemu plików sieciowych (NFS). Oczekiwane teoretyczne łączne maksimum dla testów to ~700 MB/s (3,5 GB/s) zapisu i ~1 GB/s odczytu (5 GB/s) na węzeł.
(9) węzłów obliczeniowych to serwery Dell PowerEdge FC630 z systemem CentOS v7.3.1611, każdy skonfigurowany z procesorem 2x18C/36T-Intel Xeon® E5-2697 v4 @ 2,30GHz z 512GB pamięci RAM. Lokalna pamięć masowa to 2 dyski SSD w macierzy RAID 1 sformatowane jako XFS zarówno dla systemu operacyjnego, jak i miejsca na zapas lub rozlane pliki.
Pojawiły się również trzy dodatkowe serwery brzegowe, które zostały wykorzystane do obsługi obciążenia YCSB.
Sieć zaplecza między węzłami obliczeniowymi a Isilon zapewnia 10 Gb/s z dużymi ramkami (MTU=9162) dla kart sieciowych i portów przełącznika.
Elementy konfiguracji testowej Hadoop (Rysunek 1)
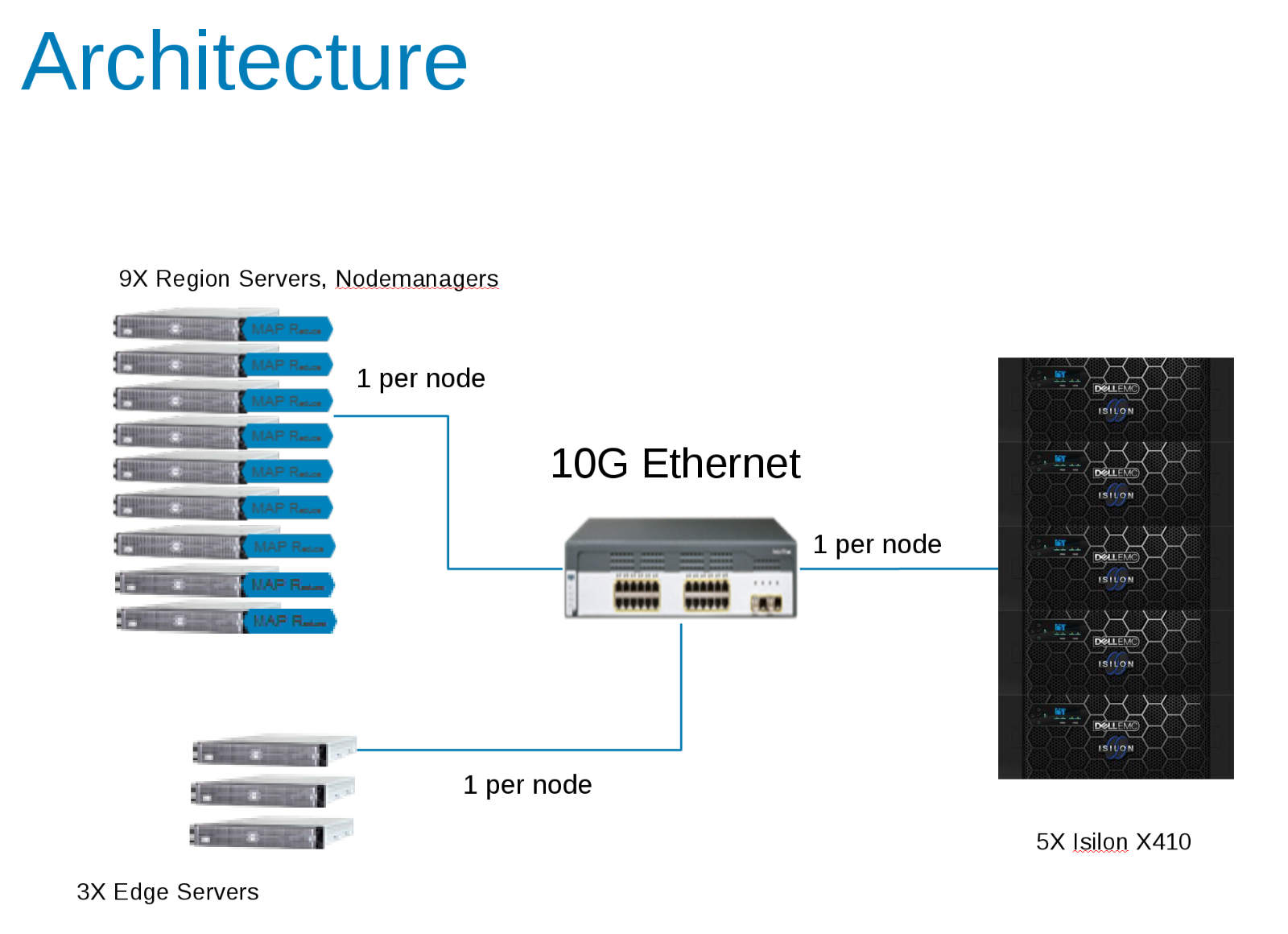
CDH 5.10 został skonfigurowany do pracy w strefie dostępu w klastrze Isilon. Konta usług zostały utworzone u lokalnego dostawcy Isilon i lokalnie w plikach /etc/passwd klienta. Wszystkie testy zostały przeprowadzone przy użyciu podstawowego klienta testowego bez specjalnych uprawnień.
Statystyki Isilon były monitorowane zarówno za pomocą IIQ, jak i pakietu Grafana/Data Insights. Statystyki CDH były monitorowane za pomocą Cloudera Manager, a także za pomocą Grafana.
Testy wstępne
Pierwsza seria testów miała na celu określenie istotnych parametrów po stronie HBASE, które wpłynęły na ogólną wydajność. Do wygenerowania obciążenia dla HBASE użyto narzędzia YCSB. Ten wstępny test został przeprowadzony przy użyciu jednego klienta (serwera brzegowego) przy użyciu fazy obciążenia YCSB i 40 milionów wierszy. Ta tabela została usunięta przed każdym uruchomieniem.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs — maksymalna liczba plików dziennika zapisu z wyprzedzeniem (WAL) — ta wartość pomnożona przez rozmiar bloku systemu plików HDFS (dfs.blocksize) to rozmiar pliku WAL, który musi zostać odtworzony w przypadku awarii serwera. Wartość ta jest odwrotnie proporcjonalna do częstotliwości przepłukiwania dysku.
- hbase.wal.regiongrouping.numgroups — w przypadku korzystania z wielu funkcji WAL systemu plików HDFS jako WALProvider ustawia to liczbę dzienników zapisu z wyprzedzeniem, które powinny być uruchamiane przez każdy serwer RegionServer. Wyniki pokazują liczbę potoków systemu plików HDFS. Zapisy dla danego regionu przechodzą tylko do jednego potoku, rozkładając łączne obciążenie RegionServer.
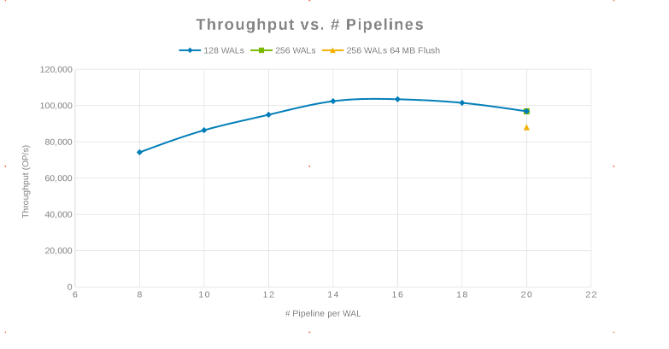
Przepływność w porównaniu z liczbą potoków (Rysunek 2)
Opóźnienie w porównaniu z liczbą potoków (Rysunek 3)
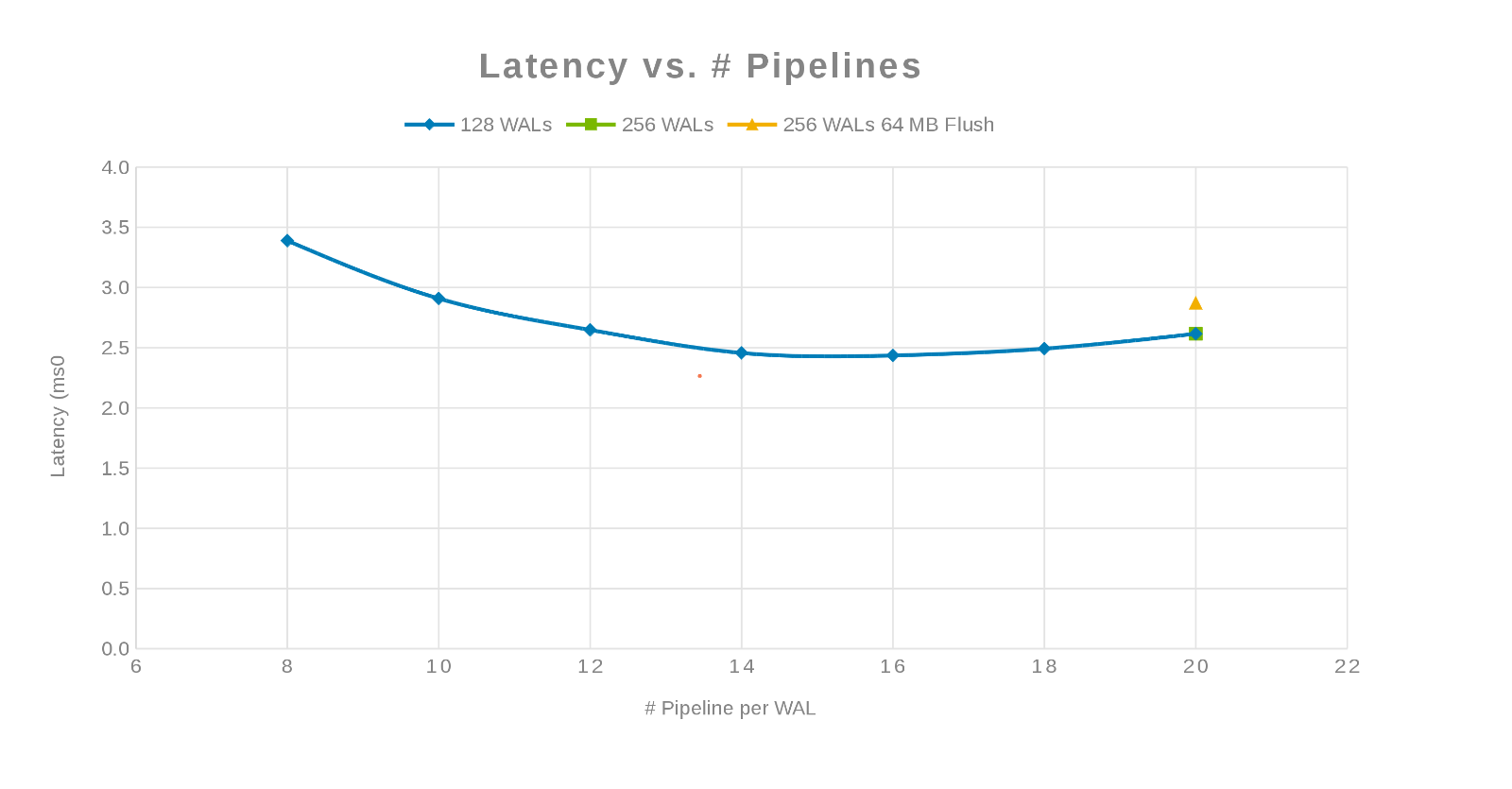
Filozofia polegała na tym, aby zrównoleglić jak najwięcej pism. Osiągnięcie tego celu odbywa się poprzez zwiększenie liczby WAL, a następnie liczby wątków (potoków) na WAL. Poprzednie dwa wykresy pokazują, że dla danej liczby dla "maxlogs", 128 lub 256, nie jest pokazana żadna rzeczywista zmiana. Oznacza to, że test tak naprawdę nie wpływa na wyniki po stronie klienta. Liczba "potoków" na plik była zróżnicowana, co wykazało trend wskazujący parametr wrażliwy na zrównoleglenie. Następne pytanie dotyczy tego, gdzie klaster Isilon "przeszkadza" w korzystaniu z we/wy dysku, sieci, procesora lub OneFS. Aby odpowiedzieć na to pytanie, spójrz na raport statystyczny Isilon.
Wykorzystanie i obciążenie sieci Isilon podczas testu (Rysunek 4)
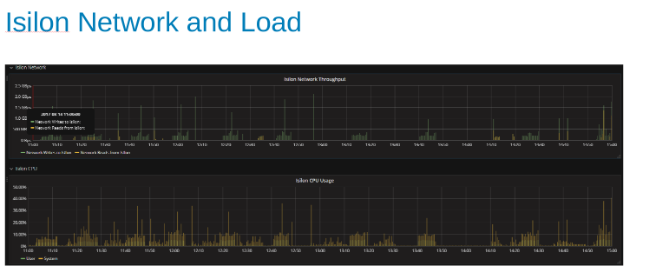
Wykresy sieci i procesorów wskazują, że klaster Isilon jest w niepełnym stopniu wykorzystywany i można w nim wykonać dodatkowe zadania. Procesor CPU wynosiłby > 80%, a przepustowość sieci byłaby większa niż 3 GB/s.
Wykresy statystyk protokołu HDFS i wykorzystania procesora przy obciążeniu protokołu HDFS (Rysunek 5)
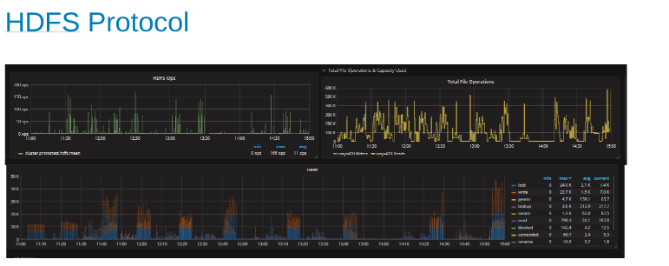
Te wykresy przedstawiają statystyki protokołu HDFS i sposób translacji danych wyjściowych przez OneFS. Operacje HDFS są wielokrotnościami pliku dfs.blocksize, który w tym przypadku ma rozmiar 256 MB. Ciekawostką jest to, że wykres "Heat" pokazuje operacje na plikach OneFS oraz korelację zapisów i blokad. W takim przypadku baza HBase dołącza do WAL, więc OneFS blokuje plik WAL dla każdego dołączonego zapisu. Jest to oczekiwane w przypadku stabilnych zapisów w klastrowym systemie plików. Wydaje się, że przyczyniają się one do czynnika ograniczającego w tym zestawie testów.
Aktualizacje bazy danych HBase
Następny test polegał na przeprowadzeniu dalszych eksperymentów, aby dowiedzieć się, co dzieje się na dużą skalę. Zostanie utworzona tabela składająca się z 1 miliarda wierszy, której wygenerowanie zajęło godzinę. Uruchamiany jest test YCSB, który zaktualizował 10 milionów wierszy przy użyciu ustawień "workloada" (odczyt/zapis 50/50). Ten test został przeprowadzony na jednym kliencie. Test przeprowadzono w funkcji liczby wątków YCSB, dzięki czemu można wygenerować jak największą przepustowość. Zastosowano również pewne dostrajanie i uaktualniono OneFS do wersji 8.0.1.1, która zawiera poprawki wydajności usługi węzła danych. Poniższy wykres przedstawia wzrost wydajności w porównaniu z poprzednim zestawem przebiegów. W przypadku tych przebiegów hbase.regionserver.maxlogs jest ustawiona wartość 256 i hbase.wal.regiongrouping.numgroups na 20.
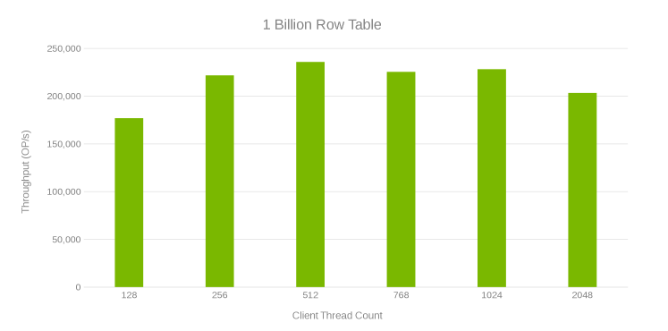
Przepływność i liczba wątków podczas aktualizowania tabeli z 1 miliardem wierszy (Rysunek 6)
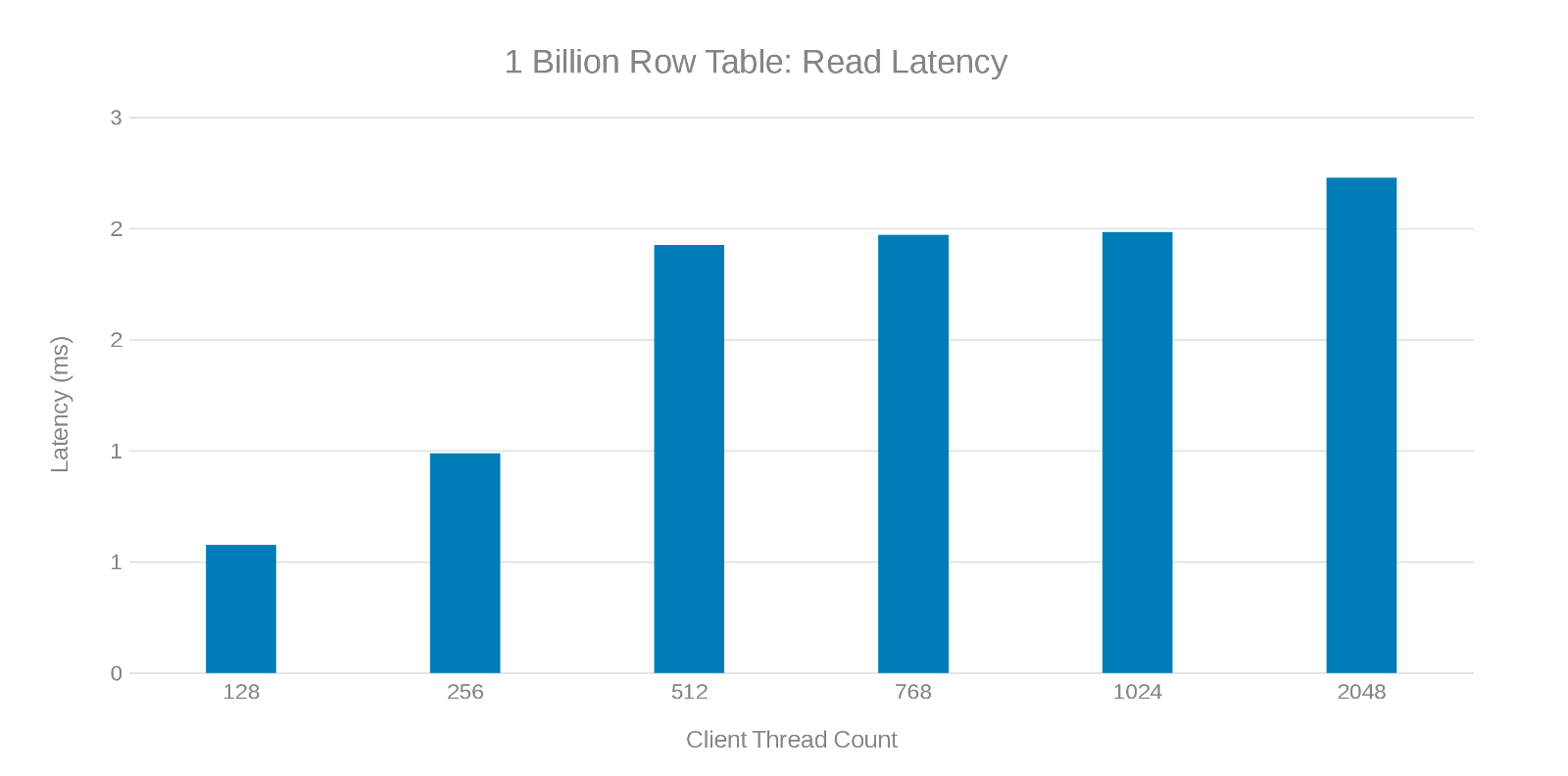
Opóźnienie odczytu podczas aktualizowania tabeli z 1 miliardem wierszy (Rysunek 7)
Aktualizuj opóźnienie podczas aktualizowania tabeli z 1 miliardem wierszy (Rysunek 8)
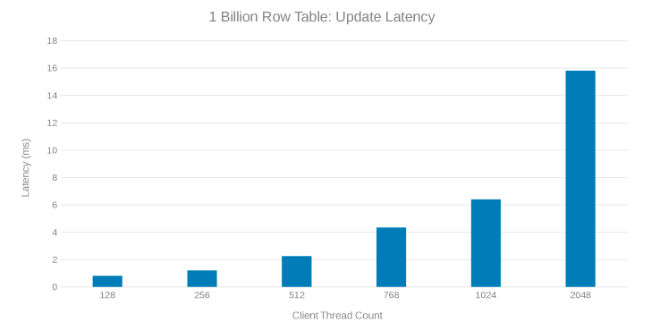
Przegląd tych przebiegów testowych pokazuje wyraźny spadek przy dużej liczbie wątków, co może być problemem po stronie Isilon lub klienta. Testy pokazują imponujące 200 tysięcy operacji na sekundę przy opóźnieniu aktualizacji wynoszącym < 3 ms. Każdy z testów aktualizacji był szybki i można go było uruchamiać jeden po drugim. Poniższy wykres przedstawia równomierną równowagę między węzłami Isilon dla każdego przebiegu testu.
Wykres ciepła wskazujący obciążenie robocze dla każdego węzła w klastrze Isilon (Rysunek 9)
Wykres ogrzewania pokazuje, że operacje na plikach są zapisami i blokadami odpowiadającymi naturze dołączania procesów WAL.
Skalowanie serwera regionalnego
Kolejnym testem było określenie, jak węzły Isilon (pięć węzłów) będą radzić sobie z różną liczbą serwerów regionalnych. Ten sam skrypt aktualizacji uruchomiony w poprzednim teście został uruchomiony z użyciem tabeli z miliardem wierszy i aktualizacją zawierającą 10 milionów wierszy przy użyciu polecenia "workloada". W teście użyto jednego klienta z wątkami YCSB ustawionymi na 51. Stosowane jest to samo ustawienie dla maxlogs i potoków (odpowiednio 256 i 20).
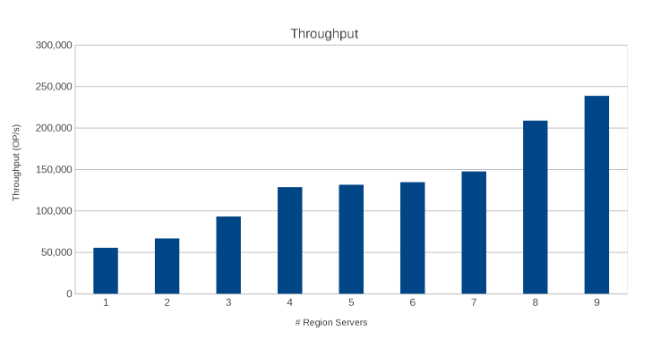
Przepływność na serwerach regionalnych (Rysunek 10)
Opóźnienie na serwerach regionalnych (Rysunek 11)
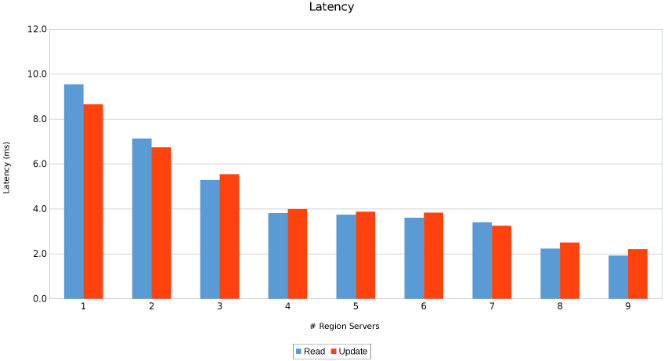
Wyniki są pouczające, choć nie zaskakujące. Skalowalny charakter HBase w połączeniu ze skalowanym w poziomie charakterem Isilon wskazuje, że im więcej, tym lepiej. Ten test jest zalecany dla klientów do uruchomienia w ich środowiskach w ramach własnego ćwiczenia ustalania rozmiaru. W tym przypadku mamy do czynienia z dziewięcioma serwerami, które naciskają na pięć węzłów Isilon i wygląda na to, że jest jeszcze miejsce na więcej, zanim osiągną punkt malejących zwrotów.
Więcej klientów
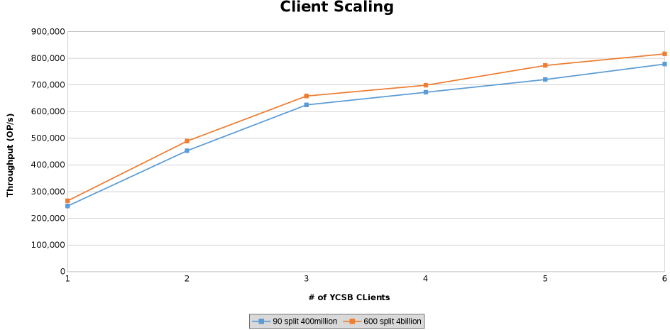
Ostatnia seria testów służyła do sprawdzenia granic konfiguracji sprzętowej. Miało to na celu określenie górnej granicy badanych parametrów. W tej serii testów do uruchamiania klientów używane są dwa dodatkowe serwery. Ponadto z każdego serwera uruchamiane są dwa klienty YCSB, co pozwala na maksymalnie sześciu klientów każdy. Każdy klient obsłużył 512 wątków, co daje łącznie 4096 wątków. Utworzono dwie różne tabele. Jedna tabela z 4 miliardami wierszy podzielona na 600 regionów, a druga z 400 milionami wierszy podzielonymi na 90 regionów.
Przedstawia to wykres przepływności operacji podczas testowania skalowania klienta (Rysunek 12) .
Pomiar opóźnienia odczytu podczas testowania skalowania klienta (Rysunek 13)
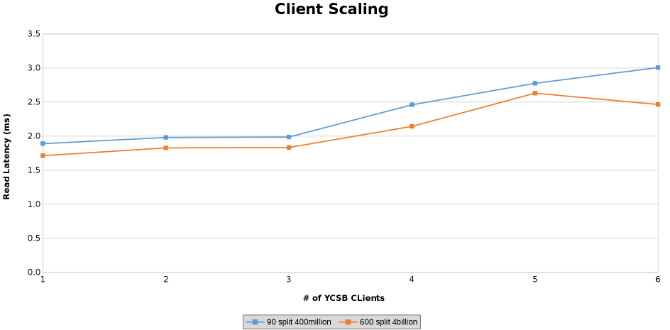
Pomiar opóźnienia aktualizacji podczas testowania skalowania klienta (Rysunek 14)
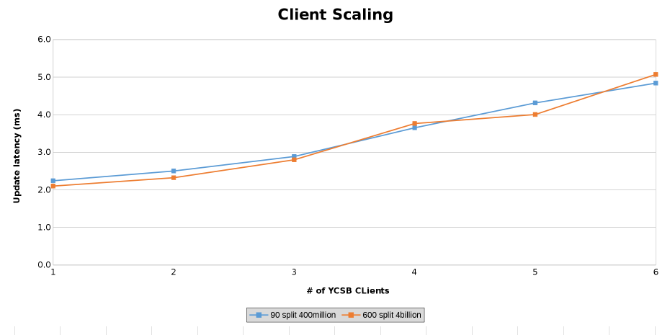
Poniższe wykresy pokazują, że rozmiar tabeli ma niewielkie znaczenie w tym teście. Wykresy ciepła Isilon ponownie pokazują, że istnieje kilka procent różnicy w liczbie operacji na plikach. Większość różnic była zgodna z różnicami między tabelą zawierającą cztery miliardy wierszy a tabelą zawierającą 400 milionów wierszy.
Porównanie ciepła obciążenia roboczego Isilon podczas aktualizowania tabeli zawierającej 400 milionów wierszy i tabeli zawierającej 4 miliardy wierszy (Rysunek 15).
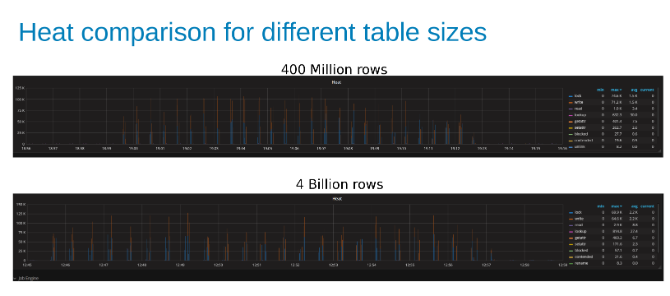
Wnioski
Baza HBase jest dobrym kandydatem do uruchamiania w Isilon, głównie ze względu na architektury skalowane w poziomie do skalowania. Baza HBase wykonuje wiele własnych buforów, a dzieląc tabelę na dużą liczbę regionów, baza HBase może skalować dane w poziomie. Innymi słowy, dobrze dba o własne potrzeby, a system plików zapewnia odporność aplikacji. Testy nie były w stanie popchnąć ładunku do punktu uszkodzenia. Jeśli baza danych HBase jest przeznaczona dla 800 000 operacji z opóźnieniem mniejszym niż 3 ms, ta architektura ją obsługuje. Baza HBase obsługuje niezliczone korekty wydajności i poprawki zarówno po stronie klienta, jak i samej bazy danych HBase. Testowanie wszystkich tych poprawek i poprawek wykraczało poza zakres tego testu.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.