PowerEdge: AMD Rome - Architecture and initial HPC performance
Summary: In the HPC world today, an introduction to AMD’s latest generation EPYC processor code-named Rome.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, October 2019
In the HPC world today, AMD’s latest generation EPYC processor code-named Rome hardly needs an introduction. We have been evaluating Rome-based systems in the HPC and AI Innovation Lab
these last few months and Dell Technologies recently announced
servers that support this processor architecture. This first blog in the Rome series discusses the Rome processor architecture, how that can be tuned for HPC performance and presents initial microbenchmark performance. Subsequent blogs describe application performance across the domains of CFD, CAE, molecular dynamics, weather simulation, and other applications.
Architecture
Rome is AMD’s 2nd generation EPYC CPU, refreshing their 1st generation Naples.
One of the biggest architectural differences between Naples and Rome that benefits HPC is the new IO die in Rome. In Rome, each processor is a multichip package consisted of up to nine chiplets as shown in Figure.1. There is one central 14 nm IO die that contains all the IO and memory functions - think memory controllers, Infinity fabric links within the socket and intersocket connectivity, and PCI-e. There are eight memory controllers per socket that support eight memory channels running DDR4 at 3200 MT/s. A single-socket server can support up to 130 PCIe Gen4 lanes. A dual-socket system can support up to 160 PCIe Gen4 lanes.
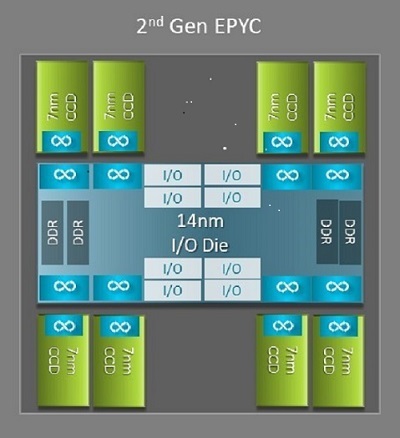
(Figure.1 Rome multichip package with one central IO die and up to eight-core dies)
Surrounding the central IO die are up to eight 7nm core chiplets. The core chiplet is called a Core Cache die or CCD. Each CCD has CPU cores based on the Zen2 microarchitecture, L2 cache and 32MB L3 cache. The CCD itself has two Core Cache Complexes (CCX), each CCX has up to four cores and 16MB of L3 cache. Figure.2 shows a CCX.

(Figure.2 A CCX with four cores and shared 16MB L3 cache)
The different Rome CPU models have different numbers of cores,
but all have one central IO die.
At the top end is a 64 core CPU model, for example, the EPYC 7702. Lstopo output shows us that this processor has 16 CCXs per socket, each CCX has four cores as shown in Figure.3 & 4, thus yielding 64 cores per socket. 16MB L3 per CCX that is 32MB L3 per CCD gives this processor 256MB L3 cache. Note, however, that the total L3 cache in Rome is not shared by all cores. The 16MB L3 cache in each CCX is independent and is shared only by the cores in the CCX as depicted in Figure.2.
A 24-core CPU like the EPYC 7402 has a 128MB L3 cache. Lstopo output in Figure.3 & 4 illustrates that this model has three cores per CCX, and eight CCX per socket.
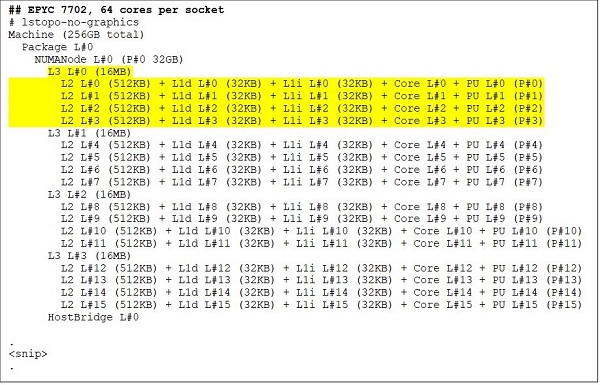
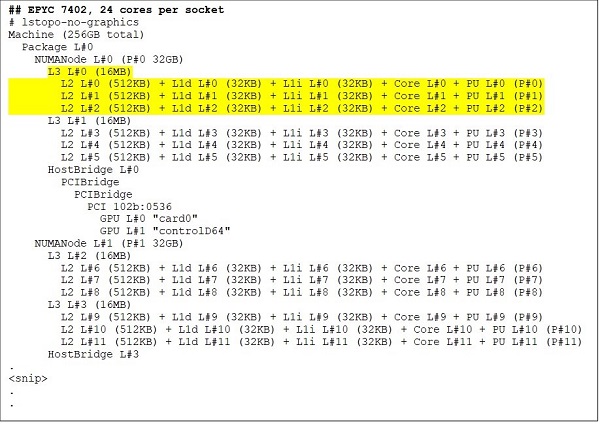
(Figure 3 & 4: Lstopo output for 64-core and 24-core CPUs)
No matter the number of CCDs, each Rome processor is logically divided into four quadrants with CCDs distributed as evenly across the quadrants as possible and two memory channels in each quadrant. The central IO die can be thought of as logically supporting the four quadrants of the socket.
BIOS options based on Rome architecture
The central IO die in Rome helps improve memory latencies over those measured in Naples. Also, it allows the CPU to be configured as a single NUMA domain enabling uniform memory access for all the cores in the socket. This is explained below.
The four logical quadrants in a Rome processor allow the CPU to be partitioned into different NUMA domains. This setting is called NUMA per socket or NPS.
- NPS1 implies that the Rome CPU is a single NUMA domain, with all the cores in the socket and all the memory in this one NUMA domain. Memory is interleaved across the eight memory channels. All PCIe devices on the socket belong to this single NUMA domain
- NPS2 partitions the CPU into two NUMA domains, with half the cores and half the memory channels on the socket in each NUMA domain. Memory is interleaved across the four memory channels in each NUMA domain
- NPS4 partitions the CPU into four NUMA domains. Each quadrant is a NUMA domain here, and memory is interleaved across the two memory channels in each quadrant. PCIe devices are local to one of four NUMA domains on the socket depending on which quadrant of the IO die has the PCIe root for that device
- Not all CPUs can support all NPS settings
Where available, NPS4 is recommended for HPC since it is expected to provide the best memory bandwidth, lowest memory latencies, and our applications tend to be NUMA-aware. Where NPS4 is not available we recommend that the highest NPS supported by the CPU model - NPS2, or even NPS1.
Given the multitude of NUMA options available on Rome-based platforms, the PowerEdge BIOS allows two different core enumeration methods under MADT enumeration. Linear enumeration numbers cores in order, filling one CCX, CCD, socket before moving to the next socket. On a 32c CPU, cores 0 through 31 are on the first socket, cores 32-63 on the second socket. Round robin enumeration numbers the cores across NUMA regions. In this case, even-numbered cores are on the first socket, odd-numbered cores on the second socket. For simplicity, we recommend linear enumeration for HPC. See Figure.5 for an example of linear core enumeration on a dual-socket 64c server configured in NPS4. In the figure, each box of four cores is a CCX, each set of eight contiguous cores is a CCD.
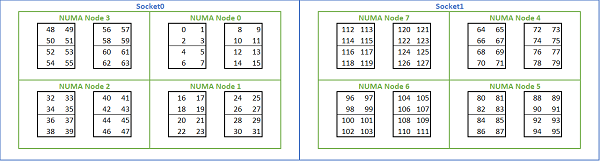
(Figure.5 Linear core enumeration on a dual-socket system, 64c per socket, NPS4 configuration on an eight CCD CPU model)
Another Rome-specific BIOS option is called Preferred IO Device. This is an important tuning knob for InfiniBand bandwidth and message rate. It allows the platform to prioritize traffic for one IO device. This option is available on one-socket and two-socket Rome platforms, and the InfiniBand device in the platform must be selected as the preferred device in the BIOS menu to achieve full message rate when all CPU cores are active.
Similar to Naples, Rome also supports hyper-threading or logical processor. For HPC, we leave this disabled, but some applications can benefit from enabling logical processor. Look for our subsequent blogs on molecular dynamics application studies.
Similar to Naples, Rome also allows CCX as NUMA Domain. This option exposes each CCX as a NUMA node. On a system with dual-socket CPUs with 16 CCXs per CPU, this setting exposes 32 NUMA domains. In this example, each socket has eight CCDs, that is 16 CCX. Each CCX can be enabled as its own NUMA domain, giving 16 NUMA nodes per socket and 32 in a two-socket system. For HPC, we recommend leaving CCX as NUMA Domain at the default option of disabled. Enabling this option is expected to help virtualized environments.
Similar to Naples, Rome allows the system to be set in Performance Determinism or Power Determinism mode. In Performance Determinism, the system operates at the expected frequency for the CPU model reducing variability across multiple servers. In Power Determinism, the system operates at the maximum available TDP of the CPU model. This amplifies part to part variation in the manufacturing process, allowing some servers to be faster than others. All servers may consume the maximum rated power of the CPU, making the power consumption deterministic, but allowing for some performance variation across multiple servers.
As you would expect from PowerEdge platforms, the BIOS has a meta option called System Profile. Selecting the Performance-Optimized system profile enables turbo boost mode, disable C-states, and set the determinism slider to Power Determinism, optimizing for performance.
Performance Results - STREAM, HPL, InfiniBand microbenchmarks
Many of our readers might have jumped straight to this section, so we dive right in.
In the HPC and AI Innovation Lab, we have built out a 64-server Rome-based cluster we are calling Minerva. In addition to the homogenous Minerva cluster, we have a few other Rome CPU samples we could evaluate. Our testbed is described in Table.1 and Table.2.
(Table.1 Rome CPU models evaluated in this study)
| CPU | Cores per Socket | Config | Base Clock | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c per CCX | 2.0 GHz | 200W |
| 7502 | 32c | 4c per CCX | 2.5 GHz | 180W |
| 7452 | 32c | 4c per CCX | 2.35 GHz | 155W |
| 7402 | 24c | 3c per CCX | 2.8 GHz | 180W |
(Table.2 Testbed)
| Component | Details |
|---|---|
| Server | PowerEdge C6525 |
| Processor | As shown in Table.1 dual-socket |
| Memory | 256 GB, 16x16GB 3200 MT/s DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| Operating System | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0.957.27.2.e17.x86_64 |
| Disk | 240 GB SATA SSD M.2 module |
STREAM
Memory bandwidth tests on Rome are presented in Figure.6, these tests were run in NPS4 mode. We measured ~270-300 GB/s memory bandwidth on our dual-socket PowerEdge C6525 when using all the cores in the server across the four CPU models listed in Table.1. When only one core is used per CCX, the system memory bandwidth is ~9-17% higher than that measured with all cores.
Most HPC workloads will either fully subscribe all the cores in the system, or HPC centers run in high throughput mode with multiple jobs on each server. Hence the all-core memory bandwidth is the more accurate representation of the memory bandwidth and memory-bandwidth-per-core capabilities of the system.
Figure.6 also plots the memory bandwidth measured on the previous generation EPYC Naples platform, which also supported eight memory channels per socket but running at 2667 MT/s. The Rome platform provides 5% to 19% better total memory bandwidth than Naples, and this is predominantly due to the faster 3200 MT/s memory. Even with 64c per socket, the Rome system can deliver upwards of 2 GB/s/core.
NOTE: A 5-10% performance variation in STREAM Triad results was measured across multiple identically configured Rome-based servers, the results below should be assumed to be the top-end of the range.
Comparing the different NPS configuration, ~13% higher memory bandwidth was measured with NPS4 as compared to NPS1 as shown in Figure.7.
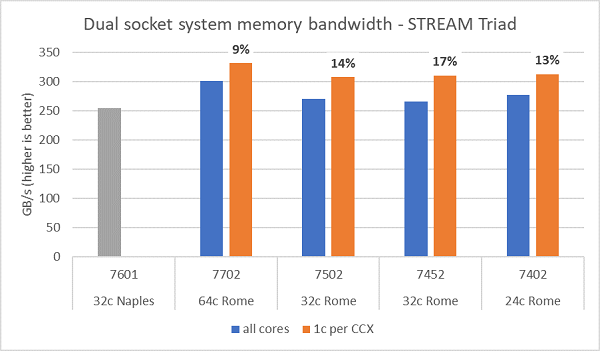
(Figure.6 Dual-socket NPS4 STREAM Triad memory bandwidth)
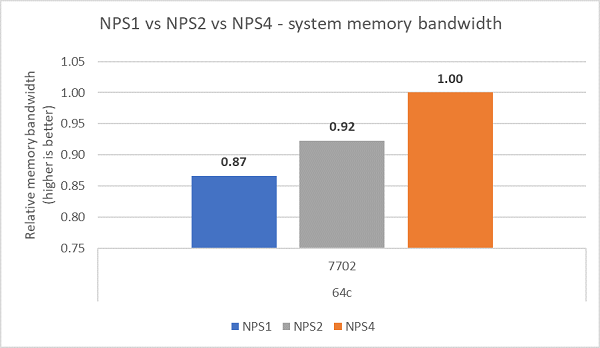
(Figure.7 NPS1 vs NPS2 vs NPS 4 Memory bandwidth)
InfiniBand bandwidth and message rate
Figure.8 plots the single-core InfiniBand bandwidth for unidirectional and bidirectional tests. The testbed used HDR100 running at 100 Gbps, and the graph shows the expected line-rate performance for these tests.
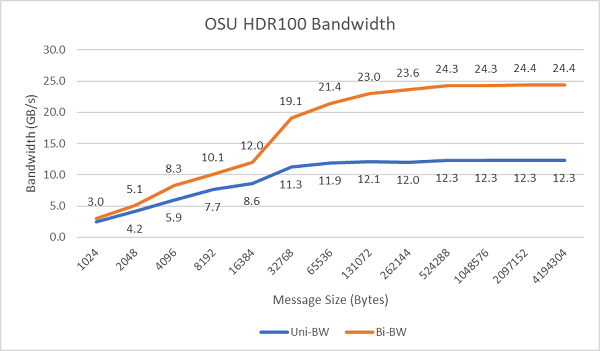
Figure.8 InfiniBand bandwidth (single-core))
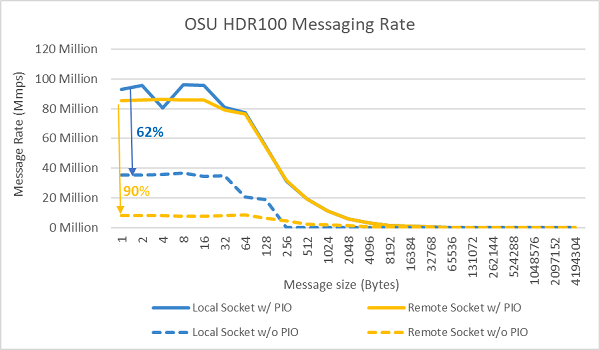
Figure.9 InfiniBand message rate (all cores))
Message rate tests were conducted next using all the cores on a socket in the two servers under test. When Preferred IO is enabled in the BIOS and the ConnectX-6 HDR100 adapter is configured as the preferred device, the all-core message rate is higher than when Preferred IO is not enabled as shown in Figure.9. This illustrates the importance of this BIOS option when tuning for HPC and especially for multinode application scalability.
HPL
The Rome microarchitecture can retire 16 DP FLOP/cycle, double that of Naples which was 8 FLOPS/cycle. This gives Rome 4x the theoretical peak FLOPS over Naples, 2x from the enhanced floating-point capability, and 2x from double the number of cores (64c vs 32c). Figure.10 plots the measured HPL results for the four Rome CPU models we tested, along with our previous results from a Naples-based system. The Rome HPL efficiency is noted as the percentage value above the bars on the graph and is higher for the lower TDP CPU models.
Tests were run in Power Determinism mode, and a ~5% delta in performance was measured across 64 identically configured servers, the results here are thus in that performance band.
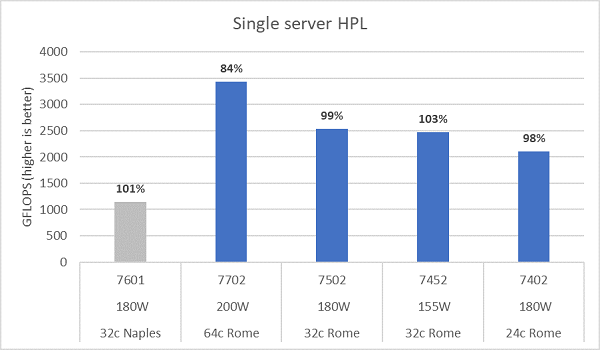
(Figure.10 Single server HPL in NPS4)
Next multinode HPL tests were performed and those results are plotted in Figure.11. The HPL efficiencies for EPYC 7452 remain above 90% at a 64-node scale, but the dips in efficiency from 102% down to 97% and back up to 99% need further evaluation.
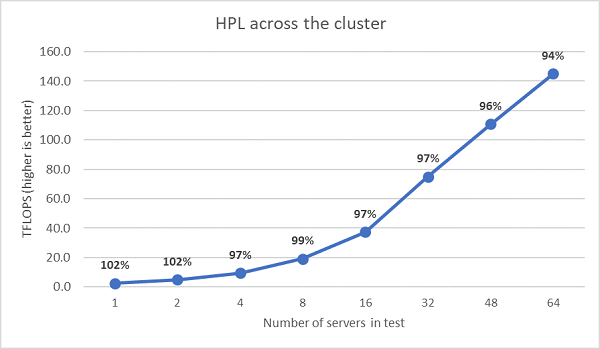
(Figure.11 Multinode HPL, dual-socket EPYC 7452 over HDR100 InfiniBand)
Summary and what is coming next:
Initial performance studies on Rome-based servers show expected performance for our first set of HPC benchmarks. BIOS tuning is important when configuring for best performance, and tuning options are available in our BIOS HPC workload profile that can be configured in the factory or set using Dell EMC systems management utilities.
The HPC and AI Innovation Lab have a new 64-server Rome-based PowerEdge cluster Minerva. Watch this space for subsequent blogs that describe application performance studies on our new Minerva cluster.
Affected Products
Mellanox Family of Adapters, PowerEdge C6525, PowerEdge C6615, PowerEdge R6515, PowerEdge R6525, PowerEdge R6615, PowerEdge R6625, PowerEdge R6715, PowerEdge R6725, PowerEdge R7515, PowerEdge R7525, PowerEdge R7615, PowerEdge R7625, PowerEdge R7715
, PowerEdge R7725, PowerEdge R7725xd
...
Article Properties
Article Number: 000137696
Article Type: How To
Last Modified: 04 Mar 2026
Version: 12
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.