Openshift Event Code: 1030NODE0001
Zusammenfassung: Vedvarende høy CPU-utnyttelse på en enkelt kontrollplannode, vil mer CPU-press sannsynligvis forårsake en failover; økning tilgjengelig CPU.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Ekstremt CPU-trykk kan føre til treg serialisering og dårlig ytelse fra kube-apiserver og etcd. Når dette skjer, er det en risiko for at klienter ser ikke-responsive API-forespørsler som utstedes igjen, noe som forårsaker enda mer CPU-trykk.
Det kan også forårsake sviktende livlighetssonder på grunn av langsom etcd-respons på backend. Hvis en kube-apiserver mislykkes under denne tilstanden, er sjansen stor for at du vil oppleve en kaskade da de gjenværende kube-apiservers også er under-provisioned.
Det kan også forårsake sviktende livlighetssonder på grunn av langsom etcd-respons på backend. Hvis en kube-apiserver mislykkes under denne tilstanden, er sjansen stor for at du vil oppleve en kaskade da de gjenværende kube-apiservers også er under-provisioned.
Ursache
Dette varselet utløses når det er en vedvarende høy CPU-utnyttelse på en enkelt kontrollplannode.
Hvor mye dette varselet haster, avgjøres av hvor lenge noden opprettholder høy CPU-bruk:
Hvor mye dette varselet haster, avgjøres av hvor lenge CPU-utnyttelsen på tvers av alle tre kontrollplannodene er høyere enn to kontrollplannoder kan opprettholde.
Hvor mye dette varselet haster, avgjøres av hvor lenge noden opprettholder høy CPU-bruk:
- Kritisk
- når CPU-bruken på en individuell kontrollplannode er større enn 90 % i mer enn 1 time.
- Advarsel
- når CPU-bruken på en individuell kontrollplannode er større enn 90 % i mer enn 5 m.
Hvor mye dette varselet haster, avgjøres av hvor lenge CPU-utnyttelsen på tvers av alle tre kontrollplannodene er høyere enn to kontrollplannoder kan opprettholde.
- Advarsel
- når CPU-utnyttelsen på tvers av alle tre kontrollplannodene er høyere enn to kontrollplannoder kan opprettholde i mer enn 10 meter.
Lösung
Diagnose:
Utfør følgende PromQL-spørringer på OCP-nettkonsollen for å få hjelp med diagnosen (Observer → Metrics → Run-spørringer).Topp 5 beholdere med mest CPU-utnyttelse på en bestemt node:
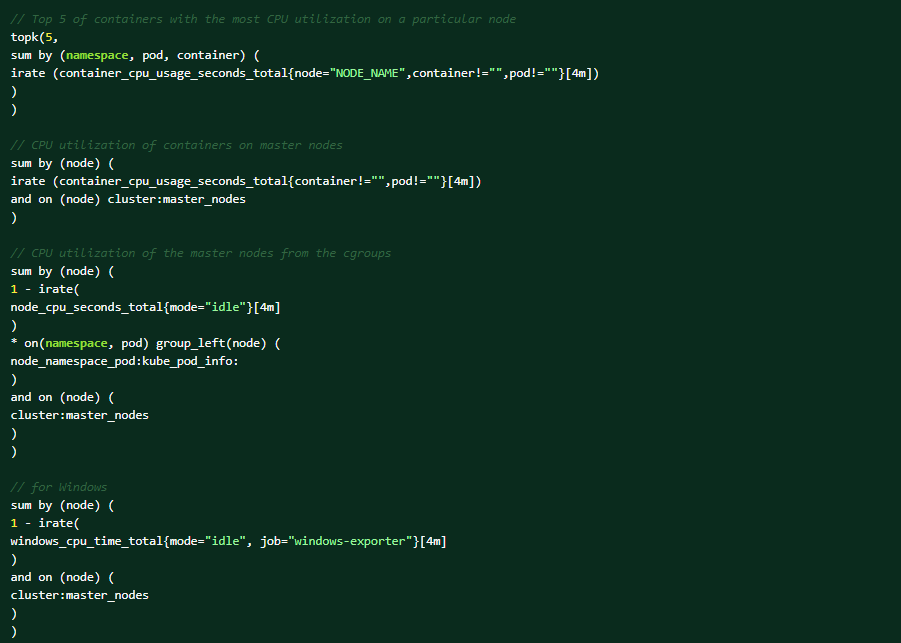
Dette er forholdene som kan utløse varselet:
- det er en ny arbeidsbelastning som genererer flere anrop til apiserver og forårsaker høy CPU-bruk. I dette tilfellet øker du CPU-en og minnet på kontrollplannodene.
- Varselet utløses basert på nodemålingene, så det kan hende at en komponent på noden forårsaker den høye CPU-bruken.
- APISERVER/ETCD behandler flere forespørsler på grunn av nye klientforsøk som forårsakes av en underliggende tilstand.
- ujevn fordeling av forespørsler til apiserver-forekomsten(e) på grunn av http2 (den multiplekser forespørsler over en enkelt TCP-tilkobling). Lastbalansererne er ikke på applikasjonslag, og forstår derfor ikke http2.
Klimatiltak:
- Hvis en arbeidsbelastning genererer belastning på apiserveren som forårsaker høy CPU-bruk, øker du CPU-en og minnet på kontrollplannodene.
- Hvis den vedvarende høye CPU-bruken skyldes en klyngeforringelse:
- Finn ut årsaken til nedbrytningen, og bestem deretter de neste trinnene tilsvarende.
Support:
Hvis alle trinnene ovenfor ikke kan løse problemet, kontakter du teknisk støtte hos Dell EMC for videre undersøkelser.
Weitere Informationen
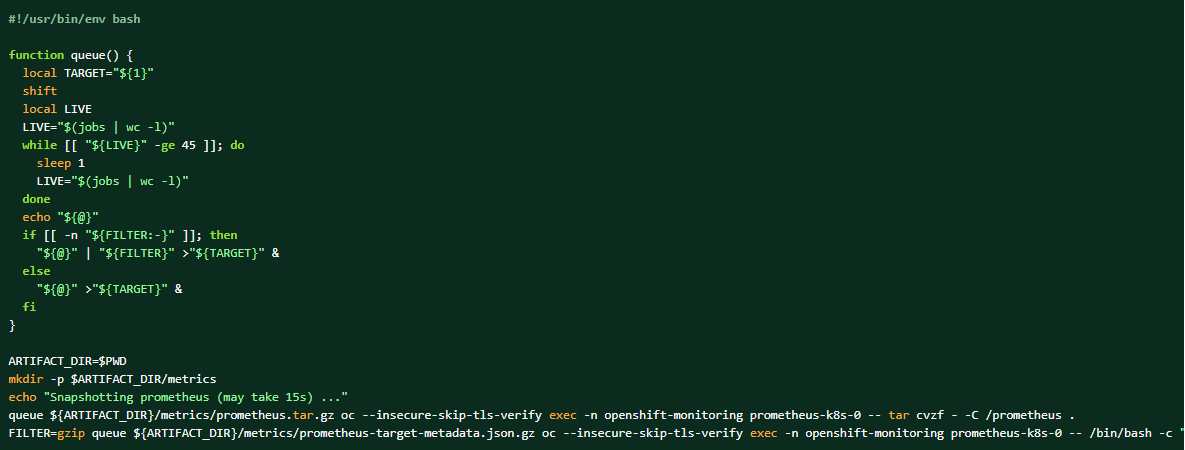
Hvis loggpakken samles inn, kan Prometheus-dataene også dumpes som komplementerende materialer.
Hvordan ta en dump av cluster prometheus-dataene:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.