Openshift Event Code: 1030NODE0001
Zusammenfassung: Aanhoudend hoog CPU-gebruik op één controleniveauknooppunt, meer CPU-druk zal waarschijnlijk een failover veroorzaken; Verhoog de beschikbare CPU.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Extreme CPU-druk kan leiden tot trage serialisatie en slechte prestaties van de kube-apiserver en etcd. Wanneer dit gebeurt, bestaat het risico dat clients niet-reagerende API-verzoeken zien die opnieuw worden uitgegeven en nog meer CPU-druk veroorzaken.
Het kan ook leiden tot defecte liveness probes als gevolg van trage etcd-responsiviteit op de backend. Als één kube-apiserver onder deze voorwaarde uitvalt, is de kans groot dat u een cascade ervaart omdat de resterende kube-apiservers ook onderbemand zijn.
Het kan ook leiden tot defecte liveness probes als gevolg van trage etcd-responsiviteit op de backend. Als één kube-apiserver onder deze voorwaarde uitvalt, is de kans groot dat u een cascade ervaart omdat de resterende kube-apiservers ook onderbemand zijn.
Ursache
Deze waarschuwing wordt geactiveerd wanneer er sprake is van een aanhoudend hoog CPU-gebruik op één controleniveauknooppunt.
De urgentie van deze waarschuwing wordt bepaald door hoe lang het knooppunt een hoog CPU-gebruik ondersteunt:
De urgentie van deze waarschuwing wordt bepaald door hoe lang het CPU-gebruik in alle drie de knooppunten van het controlevlak hoger is dan twee knooppunten van het controlevlak kunnen volhouden.
De urgentie van deze waarschuwing wordt bepaald door hoe lang het knooppunt een hoog CPU-gebruik ondersteunt:
- Kritiek
- wanneer het CPU-gebruik op een afzonderlijk controlegebied meer dan 90% is gedurende meer dan 1 uur.
- Warning
- wanneer het CPU-gebruik op een individueel controlegebied groter is dan 90% gedurende meer dan 5 m.
De urgentie van deze waarschuwing wordt bepaald door hoe lang het CPU-gebruik in alle drie de knooppunten van het controlevlak hoger is dan twee knooppunten van het controlevlak kunnen volhouden.
- Warning
- wanneer het CPU-gebruik in alle drie de knooppunten van het controlevlak hoger is dan twee knooppunten van het controlevlak meer dan 10 m kunnen volhouden.
Lösung
Diagnose:
Voer de volgende PromQL-query's uit op de OCP-webconsole voor hulp bij de diagnose (Observe → Metrics → Run queries).Top 5 van containers met het meeste CPU-gebruik op een bepaald knooppunt:
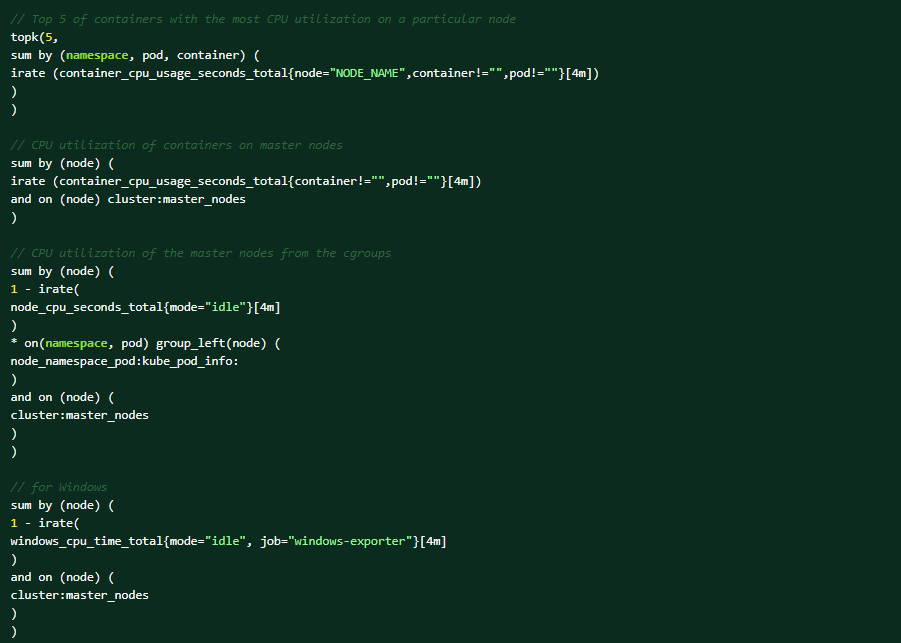
Dit zijn de omstandigheden die de waarschuwing kunnen activeren:
- er is een nieuwe workload die meer aanroepen naar de apiserver genereert en een hoog CPU-gebruik veroorzaakt. Verhoog in dit geval de CPU en het geheugen op uw controleplanknooppunten.
- de waarschuwing wordt geactiveerd op basis van de knooppuntstatistieken, dus het kan zijn dat een component op het knooppunt het hoge CPU-gebruik veroorzaakt.
- APISERVER/ETST verwerkt meer aanvragen als gevolg van nieuwe clientpogingen die worden veroorzaakt door een onderliggende aandoening.
- ongelijke verdeling van verzoeken naar de apiserver-instantie(s) als gevolg van http2 (het multiplext verzoeken via een enkele TCP-verbinding). De load balancers zijn niet op de applicatielaag, en begrijpt dus http2 niet.
Mitigatie:
- Als een workload de APISERVER belast die een hoog CPU-gebruik veroorzaakt, verhoog dan de CPU en het geheugen op uw knooppunten op het controlevlak.
- Als het aanhoudend hoge CPU-gebruik te wijten is aan een clusterdegradatie:
- Ontdek de oorzaak van de degradatie en bepaal vervolgens de volgende stappen.
Support:
Als het probleem niet met alle bovenstaande stappen kan worden opgelost, neemt u contact op met de technische support van Dell EMC voor verder onderzoek.
Weitere Informationen
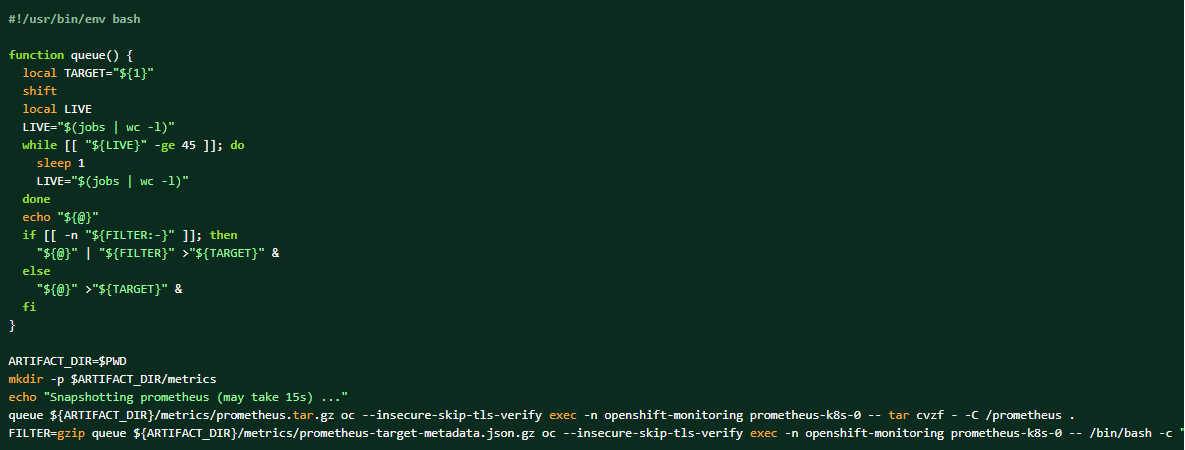
Als de logbundel wordt verzameld, kunnen de Prometheus-gegevens ook worden gedumpt als aanvullend materiaal.
Een dump maken van de prometheus-gegevens van het cluster:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.