Deep Learning-ydeevne op T4 GPU'er med MLPerf-benchmarks
Summary: Oplysninger om Turing-arkitektur, som er NVIDIA's nyeste GPU-arkitektur efter Volta-arkitekturen og den nye T4, er baseret på Turing-arkitektur.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Artikel skrevet af Rengan Xu, Frank Han og Quy Ta fra HPC og AI Innovation Lab i marts 2019
Cause
–
Resolution
Indholdsfortegnelse:
Uddrag
Turing-arkitektur er NVIDIA's nyeste GPU-arkitektur efter Volta-arkitektur, og den nye T4 er baseret på Turing-arkitektur. Det er designet til High Performance Computing (HPC), deep learning og interferens, maskinlæring, dataanalyse og grafik. Denne blog sætter tal på den dybe læringsuddannelsesydeevne for T4 GPU'er på Dell EMC PowerEdge R740-serveren med MLPerf-benchmarkpakken. MLPerf-ydeevnen på T4 sammenlignes også med V100-PCIe på samme server med samme software.
Oversigt
Dell EMC PowerEdge R740 er en 2U-rackserver med to sokler. Systemet har Intel Skylake-processorer, op til 24 DIMM'er og op til 3 V100-PCIe-processorer med dobbelt bredde eller 4 T4 GPU'er i x16 PCIe 3.0-slots. T4 er den GPU, der bruger NVIDIA's nyeste Turing-arkitektur. Forskellene i specifikationerne for T4 og V100-PCIe GPU er angivet i tabel 1. MLPerf blev valgt til at evaluere T4's ydeevne under indlæring i deep learning. MLPerf er et benchmarking-værktøj, der blev samlet af en mangfoldig gruppe fra acad and industry, herunder Google, Baidu, Intel, AMD, Harvard og University osv., til at måle hastigheden og ydeevnen for maskinindlæringssoftware og -hardware. Den oprindeligt udgivne version er v0.5 og dækker modelimplementeringer i forskellige maskinindlæringsdomæner, herunder billedklassificering, objektregistrering og segmentering, maskinoversættelse og lærning ved behov. Oversigten over MLPerf-benchmarks, der anvendes til denne evaluering, vises i tabel 2. ResNet-50 TensorFlow-implementeringen fra Googles indsendelse blev brugt, og alle andre modellers implementeringer fra NVIDIA's indsendelse blev brugt. Alle benchmarks blev kørt på metal uden en container. Tabel 3 viser den hardware og software, der anvendes til evaluering. T4-ydeevnen med MLPerf-benchmarks sammenlignes med V100-PCIe.
| Tesla V100-PCIe | Tesla T4 | |
|---|---|---|
| Arkitektur | Volta | Turing |
| CUDA-kerner | 5120 | 2560 |
| Tensor-kerner | 640 | 320 |
| Beregningsfunktion | 7.0 | 7.5 |
| GPU-ur | 1245 MHz | 585 MHz |
| Boost-ur | 1380 MHz | 1590 MHz |
| Hukommelsestype | HBM2 | GDDR6 |
| Hukommelsesstørrelse | 16 GB/32 GB | 16 GB |
| Båndbredde | 900 GB/s | 320GB/s |
| Stikbredde | Dobbeltstik | Enkeltstik |
| Enkeltpræcision (FP32) | 14 TFLOPS | 8,1 TFLOPS |
| Blandet Precision (FP16/FP32) | 112 TFLOPS | 65 TFLOPS |
| Dobbeltpræcision (FP64) | 7 TFLOPS | 254,4 GFLOPS |
| TDP | 250 W | 70 W |
Tabel 1: Sammenligningen mellem T4 og V100-PCIe
| Billedklassificering | Objektklassificering | Segmentering af objektforekomst | Oversættelse (tilbagevendende) | Tanslation (ikke-tilbagevendende) | Anbefaling | |
|---|---|---|---|---|---|---|
| Data | ImageNet | COCO | COCO | WMT E-G | WMT E-G | MovieLens-20M |
| Datastørrelse | 144 GB | 20 GB | 20 GB | 37 GB | 1,3 GB | 306 MB |
| Model | ResNet-50 v1.5 | Single-Stage-dur (SSD) | Mask-R-CNN | GNMT | Transformer | NCF |
| Ramme | TensorFlow | PyTorch | PyTorch | PyTorch | PyTorch | PyTorch |
Tabel 2: MLF Perf-benchmarks, der anvendes i evaluerings-
| Platform | PowerEdge R740 |
|---|---|
| CPU | 2x Intel Xeon Gold 6136 ved 3,0 GHz (SkyLake) |
| Hukommelse | 384 GB DDR4 ved 2666 MHz |
| Storage | 782 TB Luster |
| GPU | T4, V100-PCIe |
| OPERATIVSYSTEM og firmware | |
| Operativsystem | Red Hat® Enterprise Linux® 7,5 x86_64 |
| Linux kerne | 3.10.0-693.el7.x86_64 |
| BIOS | 1.6.12 |
| Deep Learning-relateret | |
| CUDA-compiler og GPU-driver | CUDA 10.0.130 (410.66) |
| CUDNN | 7.4.1 |
| NCCL | 2.3.7 |
| TensorFlow | nat-gpu-dev20190130 |
| PyTorch | 1.0.0 |
| MLPerf | V0,5 |
Tabel 3: Hardwarekonfigurations- og softwaredetaljer
Ydeevneevaluering
Figur 1 viser ydeevneresultaterne for MLPerf på T4 og V100-PCIe på PowerEdge R740-serveren. Seks benchmarks fra MLPerf er inkluderet. For hvert benchmark blev end-to-end-modelundervisningen udført for at nå den målmodelpræcision, der er defineret af MLPerf-udvalg. Indlæringstiden i minutter blev registreret for hvert benchmark. Følgende konklusioner kan drages ud fra disse resultater:
-
ResNet-50 v1.5-, SSD- og Mask-R-CNN-modellerne skaleres godt med et stigende antal GPU'er. For ResNet-50 v1.5 er V100-PCIe 3,6 gange hurtigere end T4. For SSD er V100-PCI 3,3x - 3,4 x hurtigere end T4. For Mask-R-CNN er V100-PCIe 2,2-2,7 gange hurtigere end T4. Med det samme antal GPU'er tager hver model næsten det samme antal epoker til at konvergere for T4 og V100-PCIe.
-
For GNMT-model blev den super lineære hastighedsopladning observeret, når der blev anvendt flere T4 GPU'er. Sammenlignet med en T4 er hastighedsup er 3,1x med to T4, og 10,4x med fire T4. Det skyldes, at modelkonvergensen påvirkes af det tilfældige seed, der bruges til indlæring af data shuffling og neural netværksvægtinitialisering. Uanset hvor mange GPU'er der bruges, kan modellen med forskellige tilfældige teknikere bruge forskellige antal epoker for at konvergere. I dette eksperiment tog modellen 12, 7, 5 og 4 epoker at konvergere med henholdsvis 1, 2, 3 og 4 T4. Og modellen tog 16, 12 og 9 epoker at konvergere med henholdsvis 1, 2 og 3 V100-PCIe. Da antallet af epoker er betydeligt anderledes selv med det samme antal T4- og V100 GPU'er, kan ydeevnen ikke sammenlignes direkte. I dette scenarie er metrikværdien for overførselshastighed en rimelig sammenligning, da den ikke afhænger af det tilfældige SEED. Figur 2 viser sammenligning af dataoverførselshastigheden for både T4 og V100-PCIe. Med det samme antal GPU'er er V100-PCIe 2,5x-3,6 gange hurtigere end T4.
-
NCF-modellen og Transformer-modellen har samme problem som GNMT. For NCF-modellen er datasættets størrelse lille, og modellen er ikke lang tid om at konvergere. derfor er dette problem ikke indlysende at bemærke i resultat figuren. Transformermodellen har det samme problem, når en GPU bruges, da modellen tog 12 epoker til at konvergere med en T4, men det tog kun 8 epoker at konvergere med en V100-PCIe. Når to eller flere GPU'er anvendes, tog modellen 4 epoker for at konvergere, uanset hvor mange GPU'er der bruges, eller hvilken GPU-type der bruges. V100-PCIe er 2,6x - 2,8 gange hurtigere end T4 i disse tilfælde.




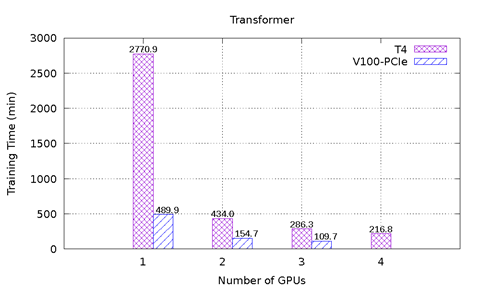

Figur 1: MLPerf-resultater på T4 og V100-PCIe

Figur 2: Sammenligning af dataoverførselshastigheden for GNMT-modellen
Konklusioner og fremtidigt arbejde
I denne blog evaluerede vi ydeevnen for T4 GPU'er på Dell EMC PowerEdge R740-serveren ved hjælp af forskellige MLPerf-benchmarks. T4's ydeevne blev sammenlignet med V100-PCIe, der bruger den samme server og software. Generelt er V100-PCIe 2,2-3,6 gange hurtigere end T4 afhængigt af egenskaberne for hvert benchmark. Det observeres, at nogle modeller er stabile, uanset hvilke tilfældige SEED-værdier der anvendes, men andre modeller, herunder GNMT, NCF og Transformer, er meget påvirket af tilfældige seed. I fremtiden vil vi finjustere hyperparametrene for at få de ustabile modeller til at konvergere med færre epoker. Vi vil også køre MLPerf på flere GPU'er og flere noder for at evaluere skalerbarheden af disse modeller på PowerEdge-servere.
*Ansvarsfraskrivelse: Med henblik på benchmarking blev fire T4 GPU'er i Dell EMC PowerEdge R740 evalueret. I øjeblikket understøtter PowerEdge R740 officielt maksimalt tre T4 i x16 PCIe-stik.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000132094
Article Type: Solution
Last Modified: 24 Sep 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.