HPC Lustreストレージ向けDell Readyソリューション: Cascade Lake Refresh
Summary: HPC Lustreストレージ向けDell Readyソリューション: Cascade Lake Refresh
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
2019年6月にHPCおよびAIイノベーション ラボのJyothi Bhaskarによって作成された記事
Cause
なし
Resolution
このブログでは、Cascade Lakeプロセッサーを搭載したDell Ready Solution for Lustreが利用可能になります。このブログでは、Lustreソリューションの最新技術仕様、更新されたソリューションの初期パフォーマンス結果、現在の結果と以前の結果の比較について説明します。 表1に示すように、EDRインターコネクトを使用して新しいアップデートを使用してソリューション スタックを構成し、インストールが期待どおりに機能することを確認し、パフォーマンス チェックを実行しました。
大規模ベース構成のアーキテクチャ図を、次の図1に示します。
サーバーとストレージのモデルは、前述と同じであることに注意してください。新しいアップデートのみが表1に表示されます。
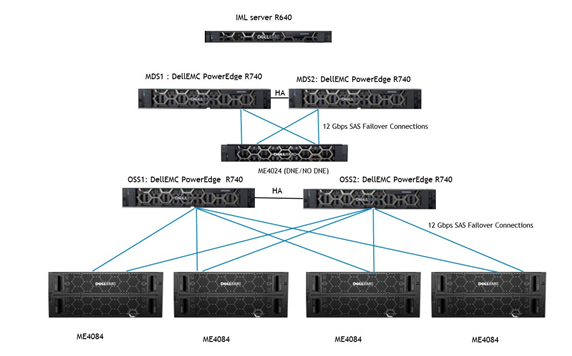
表1に示すように更新されたReady Solutionを構成し、更新されたソリューションのパフォーマンスを検証するために、IOzoneシーケンシャル、IOzoneランダム、およびMDtestベンチマークを使用してパフォーマンス チェックを実行しました。すべてのテストのベンチマーク コマンドを含むテスト方法論は、以前に使用および説明した方法と同じでした。
すべてのテストで、次の表2に記載されているクライアント テスト ベッドを使用しました。
表2に記載されているクライアントを使用して、シーケンシャルIOzoneバージョン3.487を実行しました。1つのスレッドから最大256スレッドまでのテストを実行しました。クライアントあたり複数のスレッドが8スレッドを超えています。テスト方法に従って、テストの集計データ サイズは2 TBでした。 スレッド数が32スレッド未満の場合、Lustreストライプ数32が使用され、32より大きいスレッド数の場合、Lustreストライプ数は1に設定されました。 キャッシュ効果は、前のブログで説明したように最小限に抑えられました。
このテストに使用されるLustreクライアント側チューニング パラメーターを以下に示します。

図2:シーケンシャルなN-N書き込み。Cascade Lake Lustreサーバーとクライアント

を使用した、以前の結果と現在の結果の比較図3 : シーケンシャルなN-N読み取り。Cascade Lake Lustreサーバーとクライアントを使用した、以前の結果と現在の結果の比較
図2と図3は、最新のCascade LakeベースのソリューションのIOゾーンシーケンシャルな読み取り/書き込みパフォーマンスを示し、これらの結果を以前のSkylakeベースのソリューションと比較しています。以前の結果と比較すると、シーケンシャルな読み取りと、Cascade LakeベースのクライアントとLustreサーバーを使用した書き込みのパフォーマンスが向上し、スレッド数が32スレッド未満であることが分かります。シーケンシャル書き込みのパフォーマンスが最大で2倍以上向上し、32スレッド未満の低いスレッド数での読み取りも確認できます。このパフォーマンスの差は、Cascade Lakeプロセッサー(参照リンク)に含まれるサイドチャネルエクスプロイトのハードウェア軽減に起因すると考えられます。ただし、その他の要因は、新しいソリューションのメモリーの高速化と、ソフトウェア バージョンの更新である可能性もあります。
また、スレッド数が多い場合のシーケンシャル パフォーマンスは、以前のソリューションと非常によく似ている点にも注意してください。これは、ソリューションがバックエンド ストレージ コントローラーの潜在能力を最大限に発揮すると、Cascade Lakeプロセッサーの機能拡張がパフォーマンスの向上に貢献しないためです。
表2に記載されているクライアントを使用して、ランダムIOzone(バージョン3.487)を実行しました。16、64、256スレッドでパフォーマンス チェックを実行しました。前のテスト方法と同様に、集計データ サイズは2 TBで、ストライプ サイズは4 MBに設定されました。キャッシュ効果は、前のブログで説明したように最小限に抑えられました。
このテストに使用されるLustreクライアント側チューニング パラメーターを以下に示します。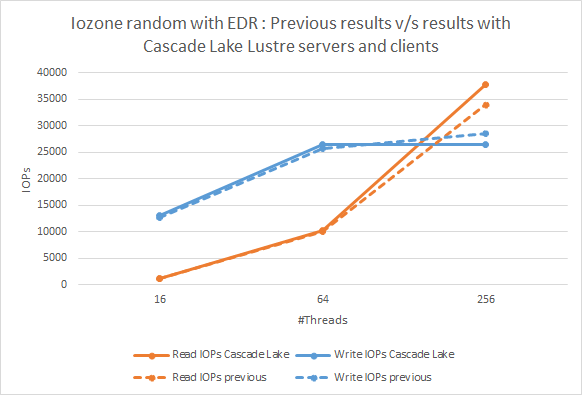
図4:IOzoneランダムN-N読み取り。Cascade Lake Lustreサーバーとクライアントを使用した以前の結果と現在の結果の比較
図4は、ランダムI/Oテストの結果を示しています。以前の結果と現在の結果を比較すると、トレンドは変わらず、観察されたパフォーマンスデルタは、実行パターンに基づいて統計的に有意でないことがわかります。
MDTestツール バージョン1.9.3を使用して、システムのメタデータ パフォーマンスを評価しました。使用されたMPIディストリビューションはインテルMPIでした。このテストは、2つのMDTとディレクトリー ストライピングを使用してDNEを使用して実行されました。テスト方法、使用したコマンド、作成されたファイルとディレクトリの数は、前のブログで説明した内容と同じです。

2) Mdtestベンチマーク
大規模ベース構成のアーキテクチャ図を、次の図1に示します。
サーバーとストレージのモデルは、前述と同じであることに注意してください。新しいアップデートのみが表1に表示されます。
図1: HPC Lustreストレージ向けDell Readyソリューション: Lベース構成のアーキテクチャ図
表1: Ready Solution for Lustreの技術仕様を更新し、以前のリリースと簡単に比較
| ハードウェア/ソフトウェア コンポーネント | 現在 | 戻る |
|---|---|---|
| OSSおよびMDSObject Storage Server( OSS )およびメタデータ サーバー( MDS )のプロセッサー | インテルXeon™ Gold 6230 CPU x 2(OSS/MDSあたり20コア@2.10GHz) | インテルXeon™ Gold 6136 x 2(12コア@ 3.00GHz) |
| Lustre( IML )サーバー用Integrated Managerのプロセッサー | インテルXeon Gold 5218 x 2(2.3GHzで16コア) | インテルXeon Gold 5118 x 2(2.3GHzで12コア) |
| OSSおよびMDSのメモリーDIMM | 12 x 32 GiB 2933 MT/s DDR4 RDIMM | 24 x 16GiB 2666MT/s DDR4 RDIMM |
| IMLサーバーのメモリーDIMM | 12 x 8GiB 2666MT/s DDR4 RDIMM | 12 x 8GB 2666MT/s DDR4 RDIMM |
| BIOS | 2.1.8以降 | 1.4.5以降 |
| OSカーネル | 3.10.0-957.1.3 | 3.10.0-862 |
| Lustreバージョン | 2.10.7 | 2.10.4 |
| IMLバージョン | 4.0.10.0 | 4.0.7.0 |
| Mellanox OFEDバージョン | 4.5-1.0.1.0 | 4.4-1 |
パフォーマンスの結果
表1に示すように更新されたReady Solutionを構成し、更新されたソリューションのパフォーマンスを検証するために、IOzoneシーケンシャル、IOzoneランダム、およびMDtestベンチマークを使用してパフォーマンス チェックを実行しました。すべてのテストのベンチマーク コマンドを含むテスト方法論は、以前に使用および説明した方法と同じでした。
すべてのテストで、次の表2に記載されているクライアント テスト ベッドを使用しました。
表2: クライアント テスト ベッド
| クライアント ノードの数 | 8 |
|---|---|
| クライアント ノード | C6420 |
| クライアント ノードあたりのプロセッサー数 | 2 x インテル(R) Xeon(R) Gold 6248(20コア@ 2.50GHz) |
| クライアント ノードあたりのメモリー | 12 16GiB 2933 MT/s RDIMM |
| BIOS | 2.2.6 |
| OSカーネル | 3.10.0-957.10.1 |
| Lustreバージョン | 2.10.7 |
| Mellanox OFED | 4.5-1.0.1.0 |
シーケンシャルIOゾーンのパフォーマンス
表2に記載されているクライアントを使用して、シーケンシャルIOzoneバージョン3.487を実行しました。1つのスレッドから最大256スレッドまでのテストを実行しました。クライアントあたり複数のスレッドが8スレッドを超えています。テスト方法に従って、テストの集計データ サイズは2 TBでした。 スレッド数が32スレッド未満の場合、Lustreストライプ数32が使用され、32より大きいスレッド数の場合、Lustreストライプ数は1に設定されました。 キャッシュ効果は、前のブログで説明したように最小限に抑えられました。
このテストに使用されるLustreクライアント側チューニング パラメーターを以下に示します。
lctl set_param osc.*.checksums=0
lctl set_param timeout=600
lctl set_param at_min=250
lctl set_param at_max=600
lctl set_param ldlm.namespaces.*.lru_size=2000
lctl set_param osc.*OST *.max_rpcs_in_flight=16
lctl set_param osc.*OST*.max_dirty_mb=1024
lctl set_param osc.*.max_pages_per_rpc=1024
lctl set_param llite.*.max_read_ahead_mb=1024
lctl set_param llite.*.max_read_ahead_per_file_mb=1024
図2:シーケンシャルなN-N書き込み。Cascade Lake Lustreサーバーとクライアント
を使用した、以前の結果と現在の結果の比較図3 : シーケンシャルなN-N読み取り。Cascade Lake Lustreサーバーとクライアントを使用した、以前の結果と現在の結果の比較
図2と図3は、最新のCascade LakeベースのソリューションのIOゾーンシーケンシャルな読み取り/書き込みパフォーマンスを示し、これらの結果を以前のSkylakeベースのソリューションと比較しています。以前の結果と比較すると、シーケンシャルな読み取りと、Cascade LakeベースのクライアントとLustreサーバーを使用した書き込みのパフォーマンスが向上し、スレッド数が32スレッド未満であることが分かります。シーケンシャル書き込みのパフォーマンスが最大で2倍以上向上し、32スレッド未満の低いスレッド数での読み取りも確認できます。このパフォーマンスの差は、Cascade Lakeプロセッサー(参照リンク)に含まれるサイドチャネルエクスプロイトのハードウェア軽減に起因すると考えられます。ただし、その他の要因は、新しいソリューションのメモリーの高速化と、ソフトウェア バージョンの更新である可能性もあります。
また、スレッド数が多い場合のシーケンシャル パフォーマンスは、以前のソリューションと非常によく似ている点にも注意してください。これは、ソリューションがバックエンド ストレージ コントローラーの潜在能力を最大限に発揮すると、Cascade Lakeプロセッサーの機能拡張がパフォーマンスの向上に貢献しないためです。
ランダムIOゾーンのパフォーマンス
表2に記載されているクライアントを使用して、ランダムIOzone(バージョン3.487)を実行しました。16、64、256スレッドでパフォーマンス チェックを実行しました。前のテスト方法と同様に、集計データ サイズは2 TBで、ストライプ サイズは4 MBに設定されました。キャッシュ効果は、前のブログで説明したように最小限に抑えられました。
このテストに使用されるLustreクライアント側チューニング パラメーターを以下に示します。
lctl set_param osc.*OST*.max_rpcs_in_flight=256
lctl set_param osc.*.max_pages_per_rpc=1024
図4:IOzoneランダムN-N読み取り。Cascade Lake Lustreサーバーとクライアントを使用した以前の結果と現在の結果の比較
図4は、ランダムI/Oテストの結果を示しています。以前の結果と現在の結果を比較すると、トレンドは変わらず、観察されたパフォーマンスデルタは、実行パターンに基づいて統計的に有意でないことがわかります。
メタデータMDtestのパフォーマンス
MDTestツール バージョン1.9.3を使用して、システムのメタデータ パフォーマンスを評価しました。使用されたMPIディストリビューションはインテルMPIでした。このテストは、2つのMDTとディレクトリー ストライピングを使用してDNEを使用して実行されました。テスト方法、使用したコマンド、作成されたファイルとディレクトリの数は、前のブログで説明した内容と同じです。
図5: MDtestを使用したメタデータ操作。 Cascade Lake Lustreサーバーとクライアントを使用した、以前の結果と現在の結果の比較
図5は、メタデータ テストの結果を示しています。現在の結果と以前の結果を比較すると、3つすべてのメタデータ操作の傾向が変わらないことが分かります。ピークファイル作成操作が75.4%向上し、ピークファイル削除操作が18%低下し、ファイル統計操作のパフォーマンスデルタがごくわずかであることに注意してください。 表1に示すように、ソリューション スタック上のソフトウェアとハードウェアのアップデートに見られるパフォーマンスの差を示すことができます。
結論
構成、インストール、およびパフォーマンスに関して、Lustre Ready Solutionのアップデートを検証および検証しました。また、収集されたパフォーマンス データもこのブログに含まれています。
Cascade LakeベースのLustreサーバーとクライアント
を使用して、以前の結果と現在の結果を比較 1)シーケンシャルIO: シーケンシャル書き込みとシーケンシャル読み取りにより、32スレッド未満の低いスレッド数で、最大で2倍以上のパフォーマンス向上が見られます。ピーク時のパフォーマンスは、以前のSkylakeベースのソリューションと同様です。
2)ランダムIO: 読み取り/書き込みパフォーマンスの傾向は非常に似ていますが、変動の実行を考慮すると、パフォーマンスデルタは統計的に有意ではありません。
3)メタデータ パフォーマンス テスト: ピーク時のファイル作成操作が最大75.4%向上しています。ファイル統計操作は、以前に観察された結果に非常に近いままであり、パフォーマンスの差はごくわずかです。ピーク時のファイル削除操作は約18%減少していますが、一般的なファイル削除操作の傾向は同じであり、他のスレッド数ではデルタはごくわずかです。
リファレンス
1) IOzoneベンチマーク2) Mdtestベンチマーク
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000144408
Article Type: Solution
Last Modified: 19 Jan 2024
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.