Dell-färdig lösning för lagring med HPC Lustre: Uppdatering av Cascade Lake
Summary: Dell-färdig lösning för lagring med HPC Lustre: Uppdatering av Cascade Lake
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Artikel skriven av Jyothi Påskar för HPC and AI Innovation Lab i juni 2019
Cause
Inget
Resolution
Med den här bloggen meddelar vi tillgängligheten för Dell Ready Solution for Lustre med Cascade Lake-processorer. I den här bloggen presenterar vi de uppdaterade tekniska specifikationerna för Lustre-lösningen, de första prestandaresultaten för den uppdaterade lösningen och en jämförelse mellan aktuella resultat och tidigare resultat. Vi konfigurerade lösningsstacken med nya uppdateringar som presenteras i tabell 1 med EDR-sammankopplingen, verifierade att installationen fungerade som förväntat och körde prestandakontroller.
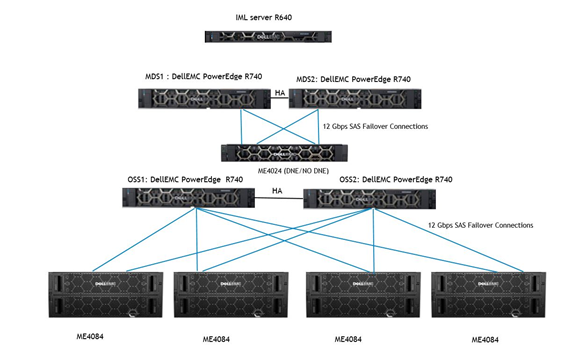
Arkitekturdiagrammet för den stora baskonfigurationen visas nedan i bild 1.
Observera att server- och lagringsmodellerna är samma som tidigare. Endast de nya uppdateringarna visas i tabell 1.
Vi konfigurerade den uppdaterade Ready Solution enligt förteckning i tabell 1 och körde prestandakontroller med IOzone sekventiella, IOzone random- och MDtest-prestandatest för att verifiera prestanda för den uppdaterade lösningen. Testmetoderna, inklusive prestandatestkommandon för alla tester, var identiska med metoden som användes och beskrevs tidigare.
För alla tester använde vi klienttestbädden enligt beskrivningen i tabell 2 nedan
Vi körde den sekventiella IOzone-versionen 3.487 med hjälp av de klienter som anges i tabell 2. Vi körde tester från en tråd upp till 256 trådar, med flera trådar per klient förbi 8 trådar. Enligt testmetoden var den aggregerade datastorleken för testet 2 TB. För lägre antal trådar som är mindre än 32 trådar, ett lustre-stripe-antal på 32 användes, och för antal trådar som är större än lika med 32 har Lustre-streckantalet ställts in på 1. Cacheeffekter minimerades enligt beskrivningen i föregående blogg.
Lustre-klientens justeringsparametrar som används för det här testet visas nedan
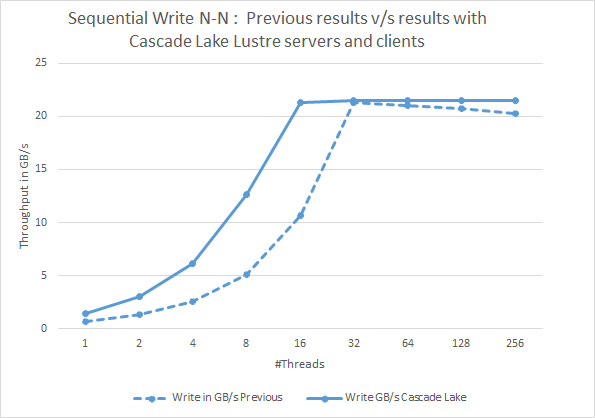
Bild 2: Sekventiella N-N-skrivningar. En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
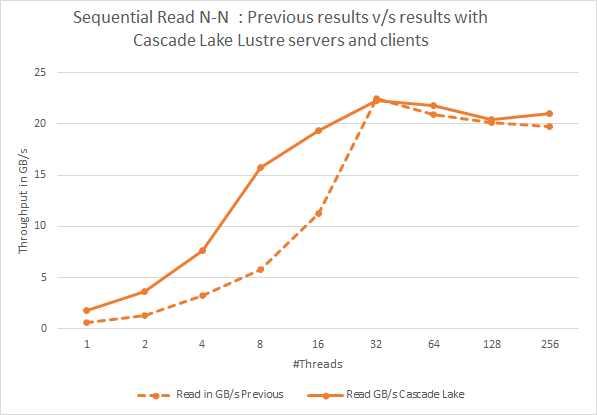
Bild 3: Sekventiella N-N-läsningar. En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
Bilderna 2 och 3 visar IOzone-sekventiell läs- och skrivprestanda för den senaste Cascade Lake-baserade lösningen och jämför dessa resultat med den tidigare Skylake-baserade lösningen. Om vi jämför med tidigare resultat ser vi att prestandaförbättring sker i sekventiella läsningar samt skrivningar med Cascade Lake-baserade klienter och Lustre-servrar, vilket ger det lägre antalet trådar under 32 trådar. Vi kan notera upp till något mer än två gånger prestandaförbättring i sekventiella skrivningar samt läsningar med lägre antal trådar under 32 trådar. Vi tror att det här prestandadelta kan bero på maskinvarubegränsning för sidokanalproblem som ingår i Cascade Lake-processorer (ref-länk). Men andra bidragande faktorer kan också vara snabbare minne i den nya lösningen och uppdaterade programvaruversioner.
Det kan också noteras att sekventiell prestanda vid högre antal trådar fortfarande är mycket liknande den tidigare lösningen. Det beror på att förbättringarna i Cascade Lake-processorerna inte bidrar till ytterligare prestandahöjning när lösningen fungerar med den fulla potentialen hos backend-lagringsstyrenheterna.
Vi körde slumpmässig IOzone, version 3.487, med hjälp av klienterna som anges i tabell 2. och körde prestandakontroller med 16, 64 och 256 trådar. Liksom vid föregående testmetod var den sammanlagda datastorleken 2 TB och stripe-storleken var inställd på 4 MB. Cacheeffekter minimerades enligt beskrivningen i föregående blogg.
Lustre-klientens justeringsparametrar som används för det här testet visas nedan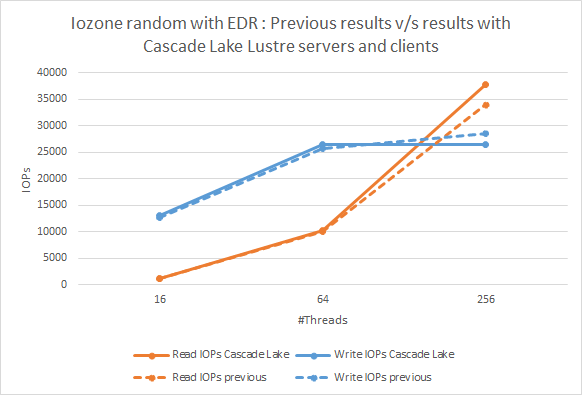
Bild 4: IOzone Random N-N Reads.En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
På bild 4 visas resultaten från de slumpmässiga I/O-testerna. Om vi jämför tidigare och aktuella resultat ser vi att trenden förblir densamma och att den observerade prestandadeltat inte är statistiskt betydande baserat på körning för att köra variation.
MDTest-verktyget version 1.9.3 användes för att utvärdera systemets metadataprestanda. Den MPI-distribution som användes var Intel MPI. Testerna kördes med DNE med två MDT och katalogstriping. Testmetoderna, det kommando som användes och antalet filer och kataloger som skapades var identiska med vad som förklaras i föregående blogg.
2) Mdtest-prestandatest
Arkitekturdiagrammet för den stora baskonfigurationen visas nedan i bild 1.
Observera att server- och lagringsmodellerna är samma som tidigare. Endast de nya uppdateringarna visas i tabell 1.
Bild 1: Dell-färdig lösning för lagring med HPC Lustre: Arkitekturdiagram över L-baskonfiguration
Tabell 1: Uppdaterade tekniska specifikationer för Ready Solution for Lustre och en snabb jämförelse med föregående version
| Maskinvaru-/programvarukomponent | Aktuell | Föregående |
|---|---|---|
| Processorer i OSS och MDSObject Storage Server (OSS) och Metadata Server (MDS) | 2 x Intel Xeon™ Gold 6230-processor med 20 kärnor vid 2,10 GHz per OSS/MDS | 2 x Intel Xeon™ Gold 6136 med 12 kärnor vid 3,00 GHz |
| Processor i IML-server (Integrated Manager for Lustre) | 2 x Intel Xeon Gold 5218 med 16 kärnor vid 2,3 GHz | 2 x Intel Xeon Gold 5118 med 12 kärnor vid 2,3 GHz |
| DIMM-minnesmoduler i OSS och MDS | 12 x 32 GiB 2933 MT/s DDR4 RDIMM-moduler | 24 x 16 GiB 2 666 MT/s DDR4 RDIMM-moduler |
| DIMM-minnesmoduler i IML-server | 12 x 8 GiB 2 666 MT/s DDR4 RDIMM-moduler | 12 x 8 GB 2 666 MT/s DDR4 RDIMM-moduler |
| BIOS | 2.1.8 och senare | 1.4.5 och senare |
| OS-kärna | 3.10.0-957.1.3 | 3.10.0-862 |
| Lustre-version | 2.10.7 | 2.10.4 |
| IML-version | 4.0.10.0 | 4.0.7.0 |
| Mellanox OFED versi | 4.5-1.0.1.0 | 4.4-1 |
Prestandaresultat
Vi konfigurerade den uppdaterade Ready Solution enligt förteckning i tabell 1 och körde prestandakontroller med IOzone sekventiella, IOzone random- och MDtest-prestandatest för att verifiera prestanda för den uppdaterade lösningen. Testmetoderna, inklusive prestandatestkommandon för alla tester, var identiska med metoden som användes och beskrevs tidigare.
För alla tester använde vi klienttestbädden enligt beskrivningen i tabell 2 nedan
Tabell 2: Klienttestbädd
| Antal klientnoder | 8 |
|---|---|
| Klientnod | C6420 |
| Processorer per klientnod | 2 x Intel(R) Xeon(R) Gold 6248 med 20 kärnor vid 2,50 GHz |
| Minne per klientnod | 12 x 16 GiB 2933 MT/s RDIMM-moduler |
| BIOS | 2.2.6 |
| OS-kärna | 3.10.0-957.10.1 |
| Lustre-version | 2.10.7 |
| Mellanox OFED | 4.5-1.0.1.0 |
Sekventiell IOzone-prestanda
Vi körde den sekventiella IOzone-versionen 3.487 med hjälp av de klienter som anges i tabell 2. Vi körde tester från en tråd upp till 256 trådar, med flera trådar per klient förbi 8 trådar. Enligt testmetoden var den aggregerade datastorleken för testet 2 TB. För lägre antal trådar som är mindre än 32 trådar, ett lustre-stripe-antal på 32 användes, och för antal trådar som är större än lika med 32 har Lustre-streckantalet ställts in på 1. Cacheeffekter minimerades enligt beskrivningen i föregående blogg.
Lustre-klientens justeringsparametrar som används för det här testet visas nedan
lctl set_param osc.*.checksums=0
lctl set_param timeout=600
lctl set_param at_min=250
lctl set_param at_max=600
lctl set_param ldlm.namespaces.*.lru_size=2000
lctl set_param osc.*OST*.max_rpcs_in_flight=16
lctl set_param osc.*OST*.max_dirty_mb=1024
lctl set_param osc.*.max_pages_per_rpc=1024
lctl set_param llite.*.max_read_ahead_mb=1024
lctl set_param llite.*.max_read_ahead_per_ file_mb=1 024
Bild 2: Sekventiella N-N-skrivningar. En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
Bild 3: Sekventiella N-N-läsningar. En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
Bilderna 2 och 3 visar IOzone-sekventiell läs- och skrivprestanda för den senaste Cascade Lake-baserade lösningen och jämför dessa resultat med den tidigare Skylake-baserade lösningen. Om vi jämför med tidigare resultat ser vi att prestandaförbättring sker i sekventiella läsningar samt skrivningar med Cascade Lake-baserade klienter och Lustre-servrar, vilket ger det lägre antalet trådar under 32 trådar. Vi kan notera upp till något mer än två gånger prestandaförbättring i sekventiella skrivningar samt läsningar med lägre antal trådar under 32 trådar. Vi tror att det här prestandadelta kan bero på maskinvarubegränsning för sidokanalproblem som ingår i Cascade Lake-processorer (ref-länk). Men andra bidragande faktorer kan också vara snabbare minne i den nya lösningen och uppdaterade programvaruversioner.
Det kan också noteras att sekventiell prestanda vid högre antal trådar fortfarande är mycket liknande den tidigare lösningen. Det beror på att förbättringarna i Cascade Lake-processorerna inte bidrar till ytterligare prestandahöjning när lösningen fungerar med den fulla potentialen hos backend-lagringsstyrenheterna.
Slumpmässig IOzone-prestanda
Vi körde slumpmässig IOzone, version 3.487, med hjälp av klienterna som anges i tabell 2. och körde prestandakontroller med 16, 64 och 256 trådar. Liksom vid föregående testmetod var den sammanlagda datastorleken 2 TB och stripe-storleken var inställd på 4 MB. Cacheeffekter minimerades enligt beskrivningen i föregående blogg.
Lustre-klientens justeringsparametrar som används för det här testet visas nedan
lctl set_param osc.*OST*.max_rpcs_in_flight=256
lctl set_param osc.*.max_pages_per_rpc=1024
Bild 4: IOzone Random N-N Reads.En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
På bild 4 visas resultaten från de slumpmässiga I/O-testerna. Om vi jämför tidigare och aktuella resultat ser vi att trenden förblir densamma och att den observerade prestandadeltat inte är statistiskt betydande baserat på körning för att köra variation.
MDtest-prestanda för metadata
MDTest-verktyget version 1.9.3 användes för att utvärdera systemets metadataprestanda. Den MPI-distribution som användes var Intel MPI. Testerna kördes med DNE med två MDT och katalogstriping. Testmetoderna, det kommando som användes och antalet filer och kataloger som skapades var identiska med vad som förklaras i föregående blogg.
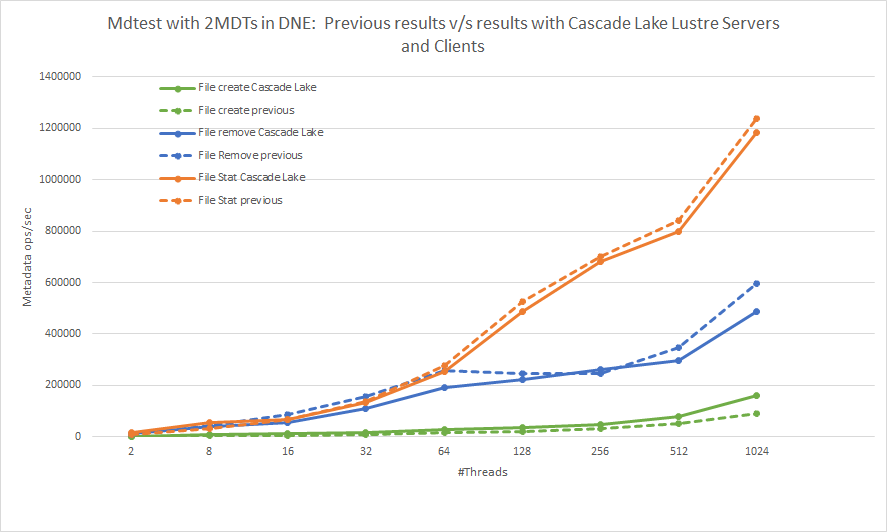
Bild 5: Metadataåtgärder med MDtest. En jämförelse av tidigare resultat med aktuella resultat med Cascade Lake Lustre-servrar och klienter
Bild 5 visar resultatet av metadatatesterna. Om vi jämför de aktuella resultaten med tidigare ser vi att trenden för alla tre metadataåtgärderna är densamma. Vi kan notera en förbättring på 75,4 % av peak file create-åtgärder, 18 % minskning av peak file remove-åtgärder och försumbar prestandadel i filstatistikåtgärder. Vi kan möjligen tillskriva prestandadelta som visas till programvaru- och maskinvaruuppdateringarna på lösningsstacken enligt tabell 1.
Slutsats
Vi har verifierat och validerat uppdateringarna till Lustre Ready-lösningen med avseende på konfiguration, installation och prestanda. Även prestandadata som har samlats in finns i den här bloggen.
Jämförelse av tidigare resultat med aktuella resultat med Cascade Lake-baserade Lustre-servrar och klienter
1) Sekventiell IO: Vi ser upp till mer än två gånger prestandaförbättring med sekventiella skrivningar och sekventiella läsningar vid lägre antal trådar under 32 trådar. Toppprestandan är fortfarande ungefär densamma som den tidigare Skylake-baserade lösningen.
2) Slumpmässig I/O: Vi kan se en mycket liknande trend vad gäller läs- och skrivprestanda med en prestandadel som inte är statistiskt viktig om vi överväger att köra varianten.
3) Prestandatest av metadata: Vi ser en förbättring av filskapandeåtgärder upp till 75,4 % som mest. Filstatistikåtgärder ligger mycket nära de resultat som tidigare observerats med försumbar prestandadel. Vi ser ungefär 18 % fall i filborttagningsåtgärder vid topp medan trenden i allmänhet för filborttagningsåtgärder förblir densamma och delta-försumbar vid andra trådantal.
Referenser
1) IOzone-prestandatest2) Mdtest-prestandatest
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000144408
Article Type: Solution
Last Modified: 19 Jan 2024
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.