Dell Ready Solution for HPC Lustre Storage: Cascade Lake 교체
Summary: Dell Ready Solution for HPC Lustre Storage: Cascade Lake 교체
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
2019년 6월 HPC and AI Innovation Lab의 Jyothi Kuskar가 작성한 문서
Cause
없음
Resolution
이 블로그를 통해 Cascade Lake 프로세서를 탑재한 Lustre용 Dell Ready Solution의 가용성을 발표했습니다. 이 블로그에서는 Lustre 솔루션의 업데이트된 기술 사양, 업데이트된 솔루션의 초기 성능 결과, 현재 결과와 이전 결과 간의 비교를 소개합니다. EDR 상호 연결이 포함된 표 1에 나와 있는 새로운 업데이트로 솔루션 스택을 구성했으며 설치가 예상대로 작동하는지 확인하고 성능 검사를 실행했습니다.
대규모 기본 구성의 아키텍처 다이어그램은 아래 그림 1에 나와 있습니다.
서버 및 스토리지 모델은 앞서 제시한 것과 동일하게 유지됩니다. 표 1에는 새 업데이트만 표시됩니다.
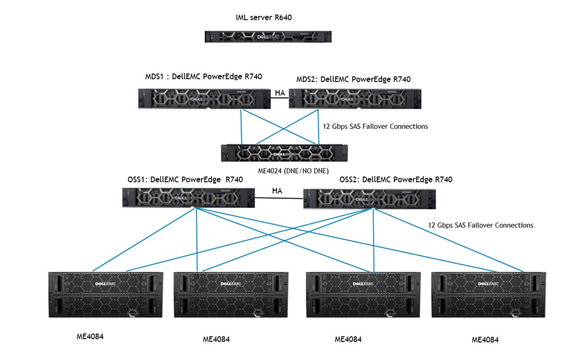
표 1에 나열된 대로 업데이트된 Ready Solution을 구성하고 IOzone 순차, IOzone 랜덤 및 MDtest 벤치마크를 사용하여 성능 검사를 실행하여 업데이트된 솔루션의 성능을 확인했습니다. 모든 테스트에 대한 벤치마크 명령을 포함한 테스트 방법론은 이전에 사용된 방법과 동일했습니다.
모든 테스트에서 아래 표 2에 설명된 대로 클라이언트 테스트침대를 사용했습니다.
표 2에 나열된 클라이언트를 사용하여 순차 IOzone 버전 3.487을 실행했습니다. 단일 스레드에서 최대 256개의 스레드까지 테스트를 실행했습니다. 클라이언트당 스레드가 8개 이상인 경우 테스트 방법에 따라 테스트의 총 데이터 크기는 2TB였습니다. 스레드 수가 32개 미만인 경우 Lustre 스트라이프 수가 32개이고 스레드 수가 32개보다 큰 경우 Lustre 스트라이프 수가 1로 설정되었습니다. 캐싱 효과는 이전 블로그에 설명된 대로 최소화되었습니다.
이 테스트에 사용되는 Lustre 클라이언트 측 튜닝 매개변수는 아래에 나와 있습니다.
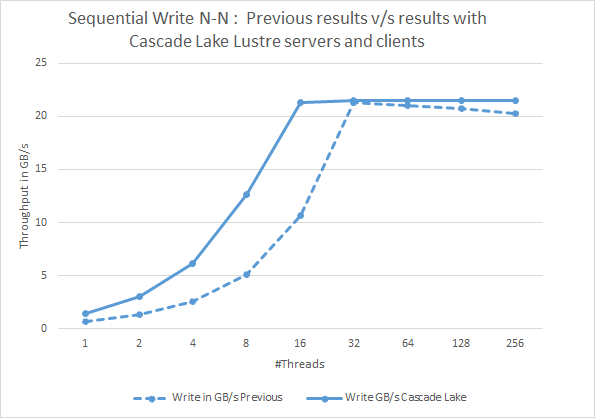
그림 2: 순차 N-N 쓰기 Cascade Lake Lustre 서버 및 클라이언트
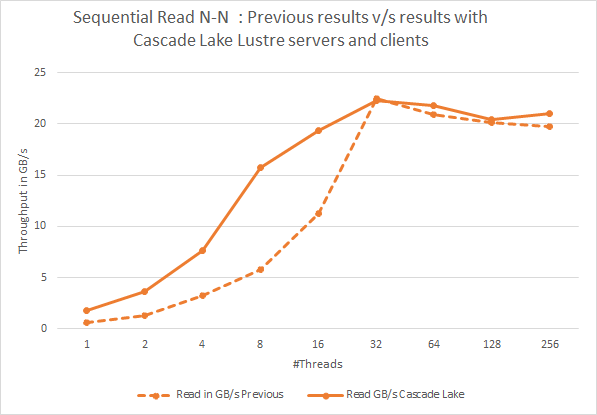
를 사용한 이전 결과와 현재 결과 비교그림 3: 순차 N-N 읽기. Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 2와 3은 최신 Cascade Lake 기반 솔루션의 IOzone 순차적 읽기 및 쓰기 성능을 제시하고 이러한 결과를 이전 Skylake 기반 솔루션과 비교합니다. 이전 결과와 비교해 볼 때, 32개 미만의 스레드 수에 대해 Cascade Lake 기반 클라이언트 및 Lustre 서버를 사용한 쓰기뿐만 아니라 순차적 읽기의 성능이 향상되었습니다. 순차 쓰기의 성능이 최대 2배 이상 향상될 뿐만 아니라 스레드 수가 32개 미만인 낮은 스레드에서 읽기를 수행할 수 있습니다. 이 성능 델타는 Cascade Lake 프로세서(참조 링크)에 포함된 사이드 채널 익스플로잇에 대한 하드웨어 완화에 기인할 수 있다고 생각합니다. 그러나 다른 요인으로는 새 솔루션의 메모리와 업데이트된 소프트웨어 버전도 더 빨라질 수 있습니다.
또한 스레드 수가 많은 순차적 성능은 이전 솔루션과 매우 유사합니다. 이는 솔루션이 백엔드 스토리지 컨트롤러의 잠재력을 최대한 발휘할 때 Cascade Lake 프로세서의 향상된 성능 향상에 기여하지 않기 때문입니다.
표 2에 나열된 클라이언트를 사용하여 랜덤 IOzone 버전 3.487을 실행했습니다. 16, 64 및 256 스레드로 성능 검사를 실행했습니다. 이전 테스트 방법과 마찬가지로 집계 데이터 크기는 2TB이고 스트라이프 크기는 4MB로 설정되었습니다. 캐싱 효과는 이전 블로그에 설명된 대로 최소화되었습니다.
이 테스트에 사용되는 Lustre 클라이언트 측 튜닝 매개변수는 아래에 나와 있습니다.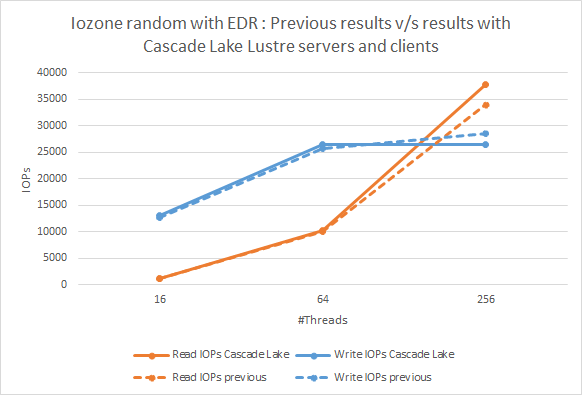
그림 4: IOzone Random N-N Reads.A Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 4는 랜덤 I/O 테스트 결과를 표시합니다. 이전 결과와 현재 결과를 비교해 보면 추세는 동일하게 유지되고 관찰된 성능 델타는 실행 편차를 기준으로 통계적으로 유의하지 않습니다.
MDTest 툴 버전 1.9.3은 시스템의 메타데이터 성능을 평가하는 데 사용되었습니다. 사용된 MPI 배포판은 인텔 MPI였습니다. 테스트는 2개의 MDT 및 디렉토리 스트라이핑을 사용하여 DNE를 사용하여 실행되었습니다. 테스트 방법론, 사용된 명령 및 생성된 파일 및 디렉토리의 수는 이전 블로그에 설명된 것과 동일합니다.
2) Mdtest 벤치마크
대규모 기본 구성의 아키텍처 다이어그램은 아래 그림 1에 나와 있습니다.
서버 및 스토리지 모델은 앞서 제시한 것과 동일하게 유지됩니다. 표 1에는 새 업데이트만 표시됩니다.
그림 1: Dell Ready Solution for HPC Lustre Storage: L 기본 구성의 아키텍처 다이어그램
표 1: Ready Solution for Lustre의 기술 사양을 업데이트하고 이전 릴리스와 빠르게 비교
| 하드웨어/소프트웨어 구성 요소 | 현재 | 이전 |
|---|---|---|
| OSS 및 MDSObject 스토리지 서버(OSS) 및 메타데이터 서버(MDS)의 프로세서 | 2개의 인텔 제온™ 골드 6230 CPU, 20코어, OSS/MDS당 2.10GHz | 2개의 인텔 제온™ 골드 6136, 12코어 , 3.00GHz |
| IML(Integrated Manger for Lustre) 서버의 프로세서 | 2개의 인텔 제온 골드 5218, 16코어 , 2.3GHz | 2개의 인텔 제온 골드 5118, 12코어 , 2.3GHz |
| OSS 및 MDS의 메모리 DIMM | 32GiB 2933MT/s DDR4 RDIMM 12개 | 16GiB 2666MT/s DDR4 RDIMM 24개 |
| IML 서버의 메모리 DIMM | 8GiB 2666MT/s DDR4 RDIMM 12개 | 8GB 2666MT/s DDR4 RDIMM 12개 |
| BIOS | 2.1.8 이상 | 1.4.5 이상 |
| OS 커널 | 3.10.0-957.1.3 | 3.10.0-862 |
| Lustre 버전 | 2.10.7 | 2.10.4 |
| IML 버전 | 4.0.10.0 | 4.0.7.0 |
| Mellanox OFED 버전 | 4.5-1.0.1.0 | 4.4-1 |
성능 결과
표 1에 나열된 대로 업데이트된 Ready Solution을 구성하고 IOzone 순차, IOzone 랜덤 및 MDtest 벤치마크를 사용하여 성능 검사를 실행하여 업데이트된 솔루션의 성능을 확인했습니다. 모든 테스트에 대한 벤치마크 명령을 포함한 테스트 방법론은 이전에 사용된 방법과 동일했습니다.
모든 테스트에서 아래 표 2에 설명된 대로 클라이언트 테스트침대를 사용했습니다.
표 2: 클라이언트 테스트침대
| 클라이언트 노드 수 | 8 |
|---|---|
| 클라이언트 노드 | C6420 |
| 클라이언트 노드당 프로세서 수 | 2개의 인텔(R) 제온(R) Gold 6248, 20코어 , 2.50GHz |
| 클라이언트 노드당 메모리 | 12 x 16GiB 2933 MT/s RDIMM |
| BIOS | 2.2.6 |
| OS 커널 | 3.10.0-957.10.1 |
| Lustre 버전 | 2.10.7 |
| Mellanox OFED | 4.5-1.0.1.0 |
순차 IOzone 성능
표 2에 나열된 클라이언트를 사용하여 순차 IOzone 버전 3.487을 실행했습니다. 단일 스레드에서 최대 256개의 스레드까지 테스트를 실행했습니다. 클라이언트당 스레드가 8개 이상인 경우 테스트 방법에 따라 테스트의 총 데이터 크기는 2TB였습니다. 스레드 수가 32개 미만인 경우 Lustre 스트라이프 수가 32개이고 스레드 수가 32개보다 큰 경우 Lustre 스트라이프 수가 1로 설정되었습니다. 캐싱 효과는 이전 블로그에 설명된 대로 최소화되었습니다.
이 테스트에 사용되는 Lustre 클라이언트 측 튜닝 매개변수는 아래에 나와 있습니다.
lctl set_param osc.*.checksums=0
lctl set_param timeout=600
lctl set_param at_min=250
lctl set_param at_max=600
lctl set_param ldlm.namespaces.*.lru_size=2000
lctl set_param osc.*OST*.max_rpcs_in_flight=16
lctl set_param osc.*OST*.max_dirty_mb=1024
lctl set_param osc.*.max_pages_per_rpc=1024
lctl set_param llite.*.max_read_ahead_mb=1024
lctl set_param llite.*.max_read_ahead_per_ file_mb=1024
그림 2: 순차 N-N 쓰기 Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 3: 순차 N-N 읽기. Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 2와 3은 최신 Cascade Lake 기반 솔루션의 IOzone 순차적 읽기 및 쓰기 성능을 제시하고 이러한 결과를 이전 Skylake 기반 솔루션과 비교합니다. 이전 결과와 비교해 볼 때, 32개 미만의 스레드 수에 대해 Cascade Lake 기반 클라이언트 및 Lustre 서버를 사용한 쓰기뿐만 아니라 순차적 읽기의 성능이 향상되었습니다. 순차 쓰기의 성능이 최대 2배 이상 향상될 뿐만 아니라 스레드 수가 32개 미만인 낮은 스레드에서 읽기를 수행할 수 있습니다. 이 성능 델타는 Cascade Lake 프로세서(참조 링크)에 포함된 사이드 채널 익스플로잇에 대한 하드웨어 완화에 기인할 수 있다고 생각합니다. 그러나 다른 요인으로는 새 솔루션의 메모리와 업데이트된 소프트웨어 버전도 더 빨라질 수 있습니다.
또한 스레드 수가 많은 순차적 성능은 이전 솔루션과 매우 유사합니다. 이는 솔루션이 백엔드 스토리지 컨트롤러의 잠재력을 최대한 발휘할 때 Cascade Lake 프로세서의 향상된 성능 향상에 기여하지 않기 때문입니다.
랜덤 IOzone 성능
표 2에 나열된 클라이언트를 사용하여 랜덤 IOzone 버전 3.487을 실행했습니다. 16, 64 및 256 스레드로 성능 검사를 실행했습니다. 이전 테스트 방법과 마찬가지로 집계 데이터 크기는 2TB이고 스트라이프 크기는 4MB로 설정되었습니다. 캐싱 효과는 이전 블로그에 설명된 대로 최소화되었습니다.
이 테스트에 사용되는 Lustre 클라이언트 측 튜닝 매개변수는 아래에 나와 있습니다.
lctl set_param osc.*OST*.max_rpcs_in_flight=256
lctl set_param osc.*.max_pages_per_rpc=1024
그림 4: IOzone Random N-N Reads.A Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 4는 랜덤 I/O 테스트 결과를 표시합니다. 이전 결과와 현재 결과를 비교해 보면 추세는 동일하게 유지되고 관찰된 성능 델타는 실행 편차를 기준으로 통계적으로 유의하지 않습니다.
메타데이터 MDtest 성능
MDTest 툴 버전 1.9.3은 시스템의 메타데이터 성능을 평가하는 데 사용되었습니다. 사용된 MPI 배포판은 인텔 MPI였습니다. 테스트는 2개의 MDT 및 디렉토리 스트라이핑을 사용하여 DNE를 사용하여 실행되었습니다. 테스트 방법론, 사용된 명령 및 생성된 파일 및 디렉토리의 수는 이전 블로그에 설명된 것과 동일합니다.
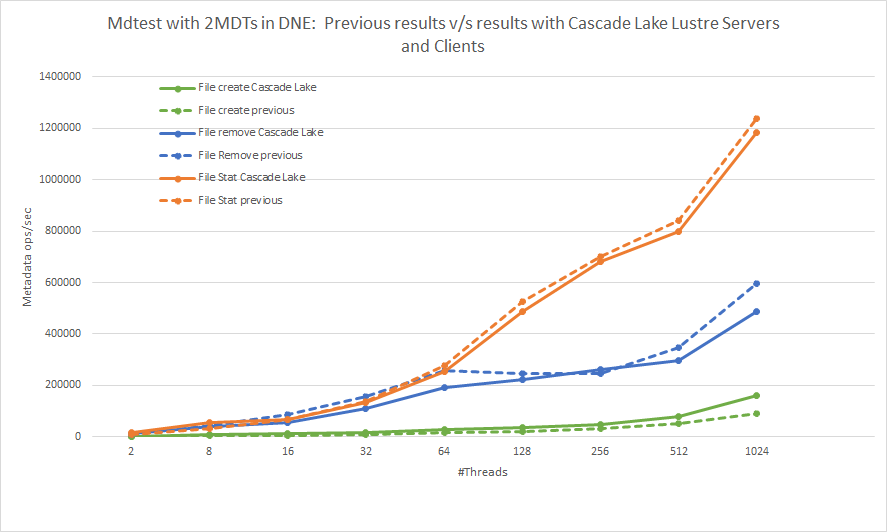
그림 5: MDtest를 사용한 메타데이터 작업 Cascade Lake Lustre 서버 및 클라이언트
를 사용한 이전 결과와 현재 결과 비교그림 5에는 메타데이터 테스트 결과가 나와 있습니다. 현재 결과를 이전과 비교했을 때 세 가지 메타데이터 작업 모두의 추세는 동일하게 유지됩니다. 최대 파일 생성 작업의 75.4% 향상, 최대 파일 제거 작업 18% 감소, 파일 통계 작업에서 성능 델타 미미를 기록할 수 있습니다. 표 1에 나와 있는 것처럼 솔루션 스택의 소프트웨어 및 하드웨어 업데이트에 표시되는 성능 델타를 지정할 수 있습니다.
결론
구성, 설치 및 성능과 관련하여 Lustre Ready Solution에 대한 업데이트를 확인하고 검증했습니다. 수집된 성능 데이터도 이 블로그에 포함되어 있습니다.
Cascade Lake 기반 Lustre 서버 및 클라이언트 1) 순차 IO를 사용하여
이전 결과를 현재 결과와 비교: 스레드 수가 32개 미만인 낮은 스레드에서 순차적 쓰기 및 순차적 읽기를 통해 최대 2배 이상의 성능 향상을 볼 수 있습니다. 최고 성능은 이전 Skylake 기반 솔루션과 유사합니다.
2) 랜덤 IO: 읽기 및 쓰기 성능에서 매우 유사한 추세를 볼 수 있으며 성능 델타는 변동을 실행하는 실행을 고려할 때 통계적으로 유의하지 않습니다.
3) 메타데이터 성능 테스트: 최대 75.4%의 파일 생성 작업이 개선되었습니다. 파일 통계 작업은 성능 델타가 미미한 상태에서 이전에 관찰된 결과와 매우 가깝게 유지됩니다. 파일 제거 작업이 최대 18% 감소하는 반면 파일 제거 작업에 대한 일반적인 추세는 동일하게 유지되고 다른 스레드 수에서는 델타를 무시할 수 있습니다.
참조
1) IOzone 벤치마크2) Mdtest 벤치마크
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000144408
Article Type: Solution
Last Modified: 19 Jan 2024
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.