When it comes to training and inference workloads for machine learning models, performance is king. Faster system performance equates to faster time to results. But how do you objectively measure system ML training and inference performance? In a word, look to MLPerf.
MLPerf is a machine learning benchmark suite from the open source community that sets a new industry standard for benchmarking the performance of ML hardware, software and services. Launched in 2018 to standardize ML benchmarks, MLPerf includes suites for benchmarking both training and inference performance. The training benchmark suite measures how fast systems can train models to a target quality metric. Each training benchmark measures the time required to train a model on the specified dataset to achieve the specified quality target. Details of the datasets, benchmark quality targets and implementation models are displayed in the table below.

At Dell Technologies, we use MLPerf to measure the performance of our servers and storage systems running machine learning and deep learning workloads, particularly those in image classification, object detection, translation, natural language processing (NLP) and reinforcement learning. Like many others in the industry, we leverage how MLPerf provides an objective way to measure and compare the performance of systems, including processors and accelerators.
To that end, we recently submitted benchmarks for the third version of the MLPerf training benchmark (v0.7), which attracted submissions from several new hardware vendors, resulting in results on a diverse set of hardware platforms. We participated in the closed division, which is intended to compare hardware platforms or software frameworks “apples-to-apples.” It requires the use of the same model and optimizer as the reference implementation.
The chart shows the increased participation in the MLPerf benchmarking competition since its start in 2018. The total number of submissions in the closed division doubled (2X) compared to the previous submission round (v0.6) and the number of submitters also increased by 3X compared to the first round (v0.5).
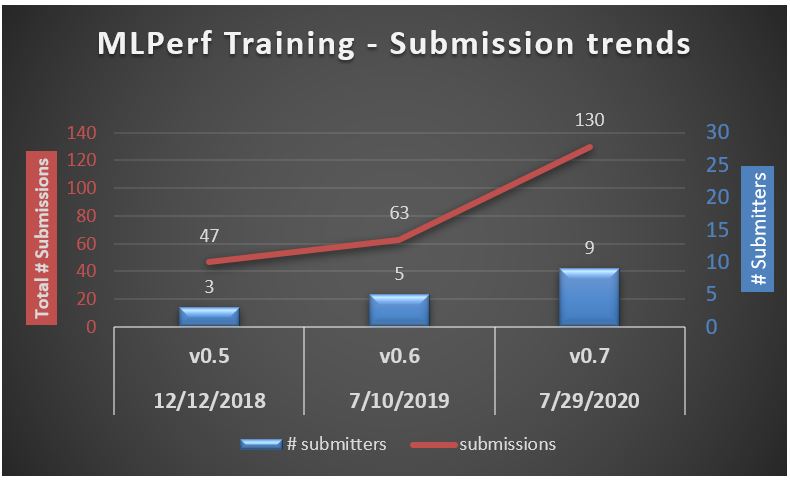
Out of the 130 submissions in the closed division, NVIDIA published the highest number of results, followed by Google and Dell — the Top 3 submitters.

Dell submitted results in 4 benchmarks, using two different ML frameworks (MXNet & PyTorch) and on two different Dell server platforms. Dell was the only vendor to publish on PCIe GPUs, which is the widely used in many Enterprise organizations.
For this exercise, the engineers from the Dell AI Innovation Labs, worked with NVIDIA to benchmark and optimize the performance of the Dell DSS 8440 server with PCIe-based NVIDIA Tesla V100S GPUs and the Dell PowerEdge C4140 server with NVIDIA Tesla V100 SXM2 GPUs and NVLink.
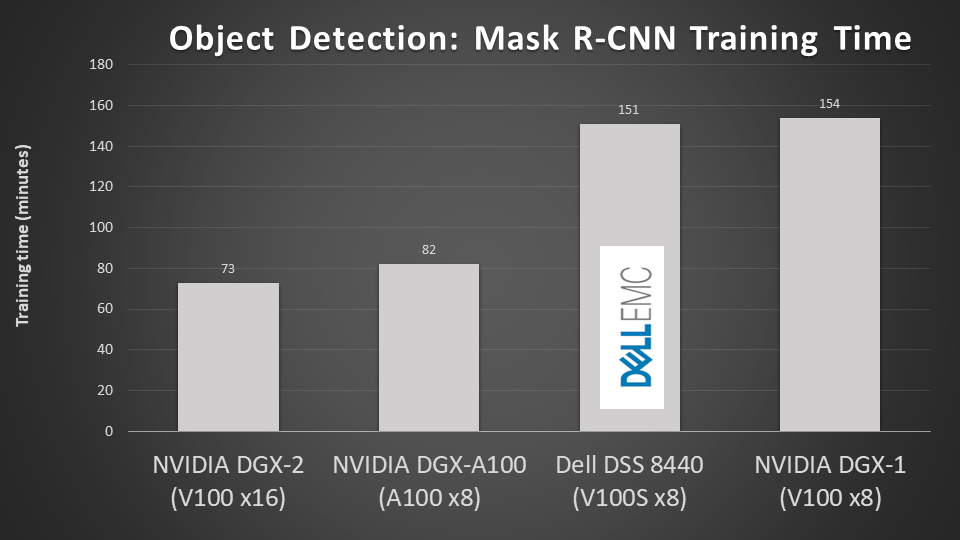
Among other outcomes, we showed that the DSS8440 server achieved particularly good results with the Resnet50 v1.5 and Mask R-CNN benchmarks, and we demonstrated that the PowerEdge C4140 server scales efficiently from one node to four nodes to train the models on 16 V100 GPUs.
The training times for Resnet50 v1.5 and Mask R-CNN are shown in the following figures.

For the full story, see the MLPerf Training v0.7 results news release and the MLPerf Training v0.7 results spreadsheet.
