

AI Solutions
Lightning: A New Performance Layer for AI Infrastructure
A high-performance ephemeral layer for demanding AI training data and inference model attention state — designed to complement the Dell AI storage portfolio.
Key takeaways:
-
- Lightning introduces a new high-performance ephemeral layer purpose-built for large-scale AI training and emerging inference context.
- Designed for sustained time-to-first-token (TTFT) and tokens-per-second (TPS), Lightning FS removes traditional storage bottlenecks that can leave GPUs underutilized in modern AI environments.
- Its fabric-bound architecture scales predictably with network bandwidth, storage media and client parallelism — enabling near-linear performance growth at cluster scale.
- Lightning complements Dell PowerScale and Dell ObjectScale, extending the Dell AI storage portfolio with a purpose-built acceleration layer for performance-critical AI pipelines.
- Optimized for transient and recomputable AI data, Lightning prioritizes efficiency, performance density and token economics over long-term persistence.
- Dell is also applying Lightning’s architectural principles to emerging inference designs, including NVIDIA CMX for distributed KV cache environments.
AI infrastructure has reached a point where incremental optimization is no longer enough. Large‑scale training and memory‑intensive inference workloads are pushing storage systems beyond the assumptions most architectures were originally designed around.
Today’s AI environments deploy thousands of GPUs operating concurrently. Network fabrics and NVMe media continue to advance rapidly with each hardware generation. The constraint that emerges is no longer capacity or features, but the efficiency and predictability of sustained data delivery at scale, often manifesting as data starvation, where compute pipelines outpace the storage architectures feeding them.
This shift has opened a clear gap in the market — large‑scale training and emerging disaggregated inference environments where architectural inefficiencies quickly compound into lost time, cost and underutilized compute.
Dell addresses this gap with Lightning — designed as an ultra‑efficient, ephemeral layer for AI infrastructure where sustained performance matters more than long‑term data retention.
Dell lightning file system and how it fits into the ecosystem
Thus, Lightning File System (Lightning FS), the world’s fastest parallel file system,1 is born. It represents net‑new Dell IP, designed from the ground up for a specific operating envelope: AI environments at the outer edge of scale, where thousands of GPUs must be supplied with data continuously and in parallel.
In a world‑class storage portfolio, different systems are optimized for different needs.
PowerScale and ObjectScale remain foundational to Dell’s AI data platform, supporting the broader AI data lifecycle — from ingest and curation to feature stores, archives and a wide range of training and inference workloads — where durability, versatility and integration are paramount.
Lightning FS complements these platforms by addressing a select but increasingly important class of use cases. It is optimized for transient, high-performance AI data pipelines — where datasets, checkpoints and inference context is short-lived, reproducible or continuously regenerated. In these environments, sustained throughput and efficiency matter more than long-term persistence.
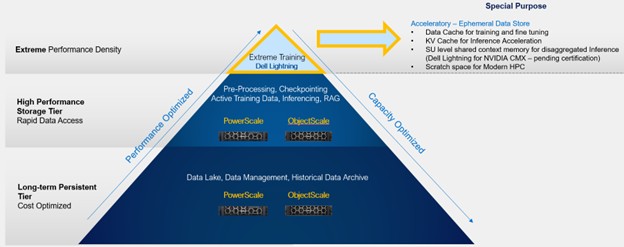
A storage accelerator — by intent
Lightning FS is a storage accelerator by design: architecturally distinct, laser-focused and built to remove storage as a limiting factor in the most demanding AI environments. It is not intended to be a general‑purpose platform.
While PowerScale and ObjectScale continue to lead in their respective domains, Lightning fills a new need — one defined by TTFT and TPS for token economics at massive scale.
At this extreme scale, even small inefficiencies accumulate rapidly, creating structural cost and slowing innovation. Meeting those demands requires a fundamentally different approach.
Fabric‑bound, not CPU-bound
Lightning FS is fabric‑bound, not CPU‑bound. Its performance scales with the fabric, the storage media and the number of clients.
As AI infrastructure grows, storage performance grows with it — predictably and linearly — until true physical limits are reached.
This behavior comes from a core architectural principle: clients play an intentional role in IO processing.
-
- POSIX file system calls are effectively terminated at the client
- Clients translate file IO into physical IOs across the fabric
- IO execution is distributed rather than serialized
- Storage media inside the Lightning FS cluster is accessed directly
From the application perspective, nothing changes. From the system perspective, centralized bottlenecks are removed from the data path.
Because Lightning FS is fabric‑bound, it naturally absorbs future infrastructure gains. Faster fabrics and denser media translate directly into higher storage performance without architectural redesign.
As models grow larger and AI systems become more memory‑intensive, Lightning ensures that storage remains aligned with the rest of the stack.
Efficiency and performance density at scale
As AI infrastructure grows, performance alone is not sufficient. Power, space and operational efficiency increasingly define what is viable.
Lightning FS was designed with performance density as a primary goal.
Rather than optimizing for peak numbers under ideal conditions, Lightning FS delivers sustained, cluster‑level performance under real AI workloads. FIO and IO500 results show near‑theoretical fabric bandwidth at the cluster level, even under random IO patterns that reflect training, checkpointing and inference behavior.
Sequential and random IO converge toward similar performance envelopes, while CPU utilization remains low. Target throughput can be achieved with fewer nodes, reducing rack footprint, power draw, cooling requirements and operational complexity.
For a deeper dive, read on in our technical overview.
Early design partners have validated our approach in practice:
“As a Design Partner working closely with Dell on the early validation of Lightning File System, we had the opportunity to assess the platform in a realistic AI and HPC‑oriented testing environment. Even at this early stage, the system demonstrated a level of performance, balance and architectural maturity that clearly reflects a strong foundational design. From a CTO perspective, it is encouraging to see a storage platform built with a clear understanding of what modern data‑intensive and AI workloads actually require.”
Prof. Maurizio Davini
CTO, University of Pisa
Lightning: What’s ahead
Lightning reflects Dell’s broader vision for the future of AI infrastructure: purpose-built performance layers that complement platforms like Dell PowerScale and Dell ObjectScale across the AI data lifecycle. Join us at Dell Technologies World 2026 to learn why Dell built Lightning FS and how it delivers predictable performance at scale for modern AI environments.
Lightning also extends into emerging inference architectures. In a follow-up blog we’ll examine how Dell intends to apply Lightning’s architectural principles to NVIDIA CMX — enabling a pod-scale, flash-based layer optimized for hot, transient and recomputable KV cache shared across GPU pods.
1 Based on Dell internal analysis, Feb. 2026. Actual performance may vary.
