Openshift-Ereigniscode: 1030NODE0001
Zusammenfassung: Bei anhaltend hoher CPU-Auslastung auf einem einzelnen Steuerungsebenen-Node führt eine höhere CPU-Belastung wahrscheinlich zu einem Failover. Erhöhen Sie die verfügbare CPU.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Eine extreme CPU-Belastung kann zu einer langsamen Serialisierung und einer schlechten Leistung von kube-apiserver und etcd führen. In diesem Fall besteht die Gefahr, dass Clients nicht reagierende API-Anforderungen sehen, die erneut ausgegeben werden, was zu noch mehr CPU-Belastung führt.
Es kann auch dazu führen, dass Liveness-Tests aufgrund der langsamen etcd-Reaktionsgeschwindigkeit im Back-End fehlschlagen. Wenn ein kube-apiserver unter dieser Bedingung ausfällt, besteht die Möglichkeit, dass es zu einer Kaskade kommt, da die verbleibenden kube-apiserver ebenfalls unzureichend bereitgestellt sind.
Es kann auch dazu führen, dass Liveness-Tests aufgrund der langsamen etcd-Reaktionsgeschwindigkeit im Back-End fehlschlagen. Wenn ein kube-apiserver unter dieser Bedingung ausfällt, besteht die Möglichkeit, dass es zu einer Kaskade kommt, da die verbleibenden kube-apiserver ebenfalls unzureichend bereitgestellt sind.
Ursache
Diese Warnmeldung wird ausgelöst, wenn ein einzelner Steuerungsebenen-Node eine anhaltend hohe CPU-Auslastung aufweist.
Die Dringlichkeit dieser Warnmeldung hängt davon ab, wie lange der Node eine hohe CPU-Auslastung aufrechterhält:
Die Dringlichkeit dieser Warnmeldung hängt davon ab, wie lange die CPU-Auslastung auf allen drei Nodes der Steuerungsebene höher ist, als zwei Nodes der Steuerungsebene aushalten können.
Die Dringlichkeit dieser Warnmeldung hängt davon ab, wie lange der Node eine hohe CPU-Auslastung aufrechterhält:
- Kritisch
- wenn die CPU-Auslastung auf einem einzelnen Steuerungsebenen-Node länger als 1 Stunde mehr als 90 % beträgt.
- Warnung
- wenn die CPU-Auslastung auf einem einzelnen Steuerungsebenen-Node mehr als 90 % für mehr als 5 Minuten beträgt.
Die Dringlichkeit dieser Warnmeldung hängt davon ab, wie lange die CPU-Auslastung auf allen drei Nodes der Steuerungsebene höher ist, als zwei Nodes der Steuerungsebene aushalten können.
- Warnung
- Wenn die CPU-Auslastung auf allen drei Steuerungsebenen-Nodes höher ist als zwei Steuerungsebenen-Nodes für mehr als 10 m aufrechterhalten werden kann.
Lösung
Diagnose:
Führen Sie die folgenden PromQL-Abfragen in der OCP-Webkonsole aus, um Hilfe bei der Diagnose zu erhalten (→ Kennzahlen- → Ausführen von Abfragen beachten).Top 5 der Container mit der höchsten CPU-Auslastung auf einem bestimmten Node:
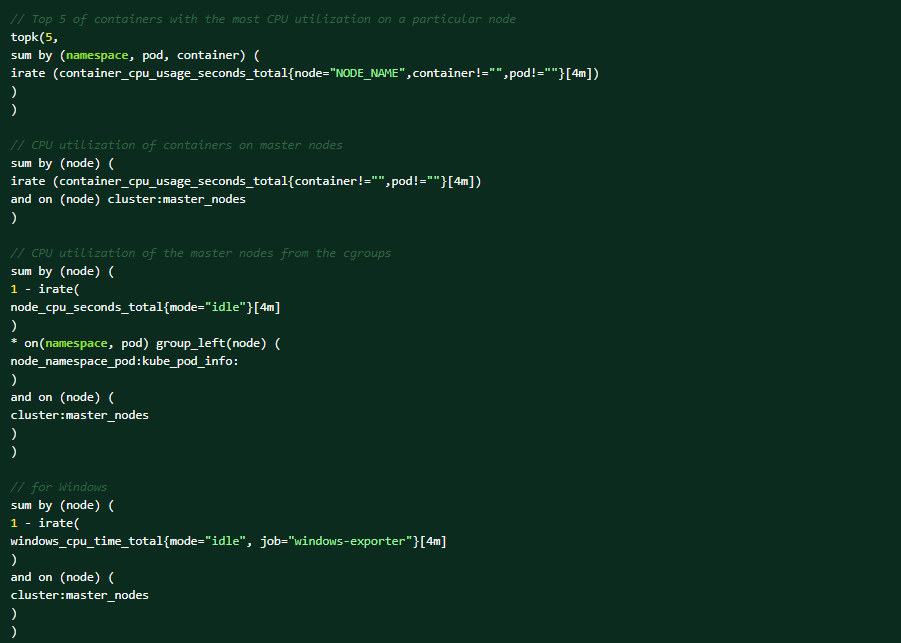
Dies sind die Bedingungen, die die Warnmeldung auslösen können:
- Es gibt eine neue Workload, die mehr Aufrufe an den API-Server generiert und eine hohe CPU-Auslastung verursacht. Erhöhen Sie in diesem Fall die CPU und den Arbeitsspeicher auf den Nodes der Steuerungsebene.
- Die Warnmeldung wird basierend auf den Node-Metriken ausgelöst. Es kann also sein, dass eine Komponente auf dem Node die hohe CPU-Auslastung verursacht.
- APIServer/etcd verarbeitet mehr Anfragen aufgrund von Clientwiederholungen, die durch eine zugrunde liegende Bedingung verursacht werden.
- Ungleichmäßige Verteilung der Anfragen an die APIserver-Instanz(en) aufgrund von HTTP2 (Multiplexing von Anfragen über eine einzige TCP-Verbindung). Die Lastenausgleichsmodule befinden sich nicht auf der Anwendungsebene und verstehen daher HTTP2 nicht.
Lösung:
- Wenn ein Workload eine Last für den API-Server erzeugt, die eine hohe CPU-Auslastung verursacht, erhöhen Sie die CPU und den Arbeitsspeicher auf den Nodes der Steuerungsebene.
- Wenn die anhaltend hohe CPU-Auslastung auf eine Clusterverschlechterung zurückzuführen ist:
- Ermitteln Sie die Ursache der Verschlechterung und legen Sie anschließend die nächsten Schritte fest.
Support:
Wenn das Problem durch die oben genannten Schritte nicht behoben werden kann, wenden Sie sich für weitere Untersuchungen an den technischen Support von Dell EMC.
Weitere Informationen
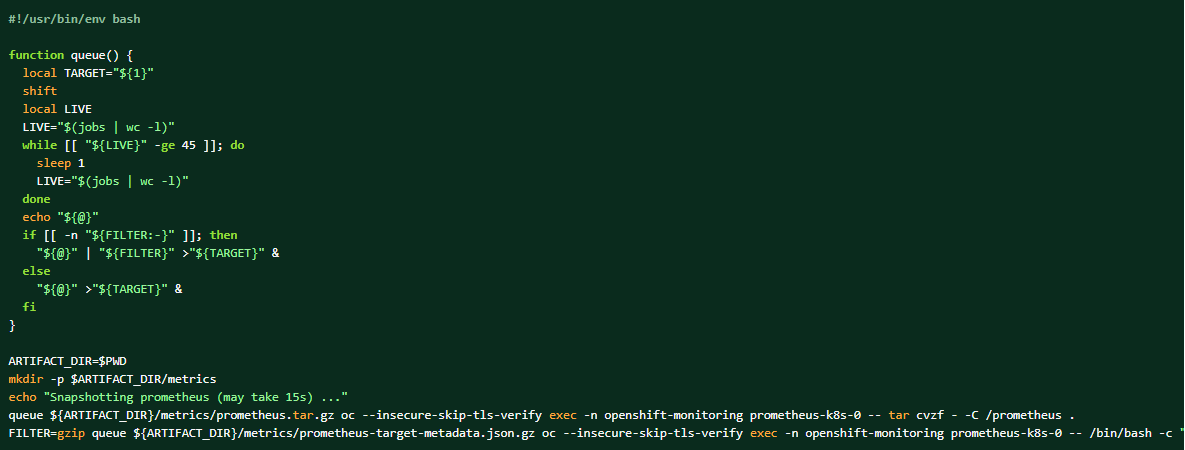
Wenn das Protokollbündel erfasst wird, können die Prometheus-Daten auch als ergänzendes Material abgelegt werden.
So erstellen Sie einen Dump der Prometheus-Daten des Clusters:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.