About 20 years ago, I started my journey into data warehousing and business analytics. Over all these years, it’s been interesting to see the evolution of big data and data warehousing, driven by the rise of artificial intelligence and widespread adoption of Hadoop.
When I started in this work, the main business challenge was how to handle the explosion of data with ever-growing data sets and, most importantly, how to gain business intelligence in as close to real time as possible. The effort to solve these business challenges led the way for a ground-breaking architecture called Massively Parallel Processing (MPP), or data sharing across multiple commodity servers with Direct Attached Storage (DAS), which kept data close to processing power. This was a move away from traditional symmetric parallel processing, where data was stored in centralized storage and accessed over networks. This worked well – for a while!
Silos
The imminent “explosion of data” present in all analytics/AI discussions is the driver for the evolution of data warehousing and business analytics. The success of the old architecture is also the reason why it had to change. You must reshuffle data quite often to keep data close to compute (whilst you run queries), while increasing data size as well as concurrent applications and users’ access to the data.
This was often resolved by creating data silos, standing up a new infrastructure for new applications, as well as performance tuning. This created a multitude of business and operational issues. While you often deal with the same data sets, they are extracted, transformed, loaded (ETL) and maintained differently across various applications, which means you have different analytical windows into the data depending on which application you are using. So which data is the source of truth? From an operational point of view, the cost to maintain various copies of the data, secure it, and maintain SLAs becomes another challenge.
The figure below shows a typical analytics environment highlighting the complexity and data duplication.
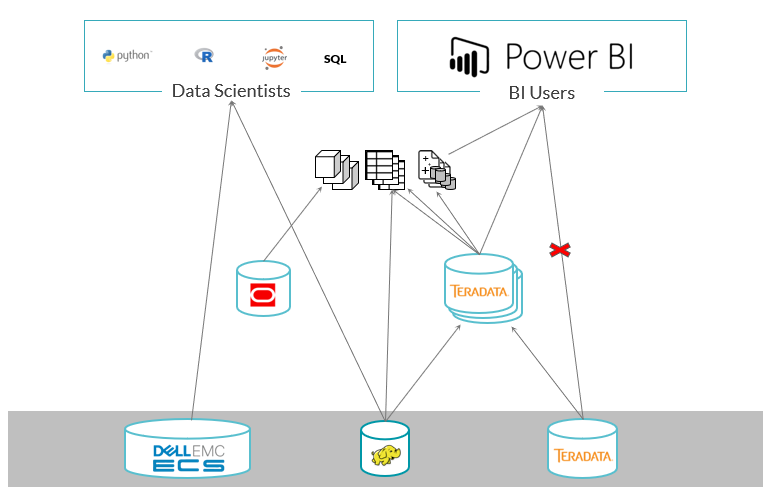
Data required
The deluge of data mentioned above is almost entirely caused by IoT and edge devices, plus an explosion in individual devices and users of social media. This is not your standard canned, transactional, and nicely-formatted SQL data. Instead, it’s usually semi-unstructured data that can sometimes only be accessed by utilizing a schema-on-read approach — which wouldn’t work for traditional SQL Data Warehouses. Also, new data types are enabling (and, perhaps even forcing) the hands of businesses to look beyond a traditional analytics approach. Today, Hadoop is a large part of many organizations’ analytical capabilities, and AI is rapidly taking off, giving businesses 360 degree analytics capabilities, from descriptive all the way to prescriptive analytics. Traditional architectures wouldn’t be able to do this, at least not at scale.
Now what do we do?
IT infrastructure must evolve to meet these data demands. Modern analytics and business intelligence now encompass all aspects of business with a much larger, more complex and multi-faceted data set and application portfolio. How do we manage all the data and applications? Simple, the answer is a “true” data lake. Account for eliminating data silos, create a single accessible data source for all applications, and eliminate data movement/replication, so organizations can control compute and storage ratios to achieve better cost with the ability to leverage best-in-class elastic cloud storage and maintain open data formats without lock-in associated with proprietary data management solutions.
At Dell Technologies, we’re working closely with some of the leading software vendors in the data lake and data warehousing arena such as Dremio, YellowBrick, and Vertica to enable our customers to seamlessly build and deploy a scalable and future-proof IT infrastructure. Dell Isilon and ECS provide best-of-breed and market-leading architecture that enables IT departments to use scale-out NAS and object storage technology that natively supports multiple protocols such as NFS, HDFS, SMB and S3. And all on the same hybrid file system offering cost effective performance, scaling and a complete set of enterprise governance features such as replication, security, backup and recovery.
The proposed architecture enables IT to eliminate multiple landing zones and ETL zones and the need to replicate data. Simply load the data files into the data lake and point your application to query data directly from the data lake. It’s that simple!
As an example, the figure below shows an open data lake architecture incorporating a data lake engine from Dremio and data lake storage via Dell Isilon and ECS. Dremio delivers lightning-fast queries directly on ECS, offering a self-service semantic layer enabling data engineers to apply security and business meaning, while also enabling analysts and data scientists to explore data and derive new virtual datasets. Dremio ensures flexibility and openness and lets you avoid vendor lock-in, directly query data across clouds or on-prem, optionally join data with existing external databases and data warehouses, and keep your data in storage that you own and control.

Dell Technologies will continue partnering with key ISVs such as Dremio, Yellowbrick and Greenplum, to deliver AI and Data Analytics solutions that will allow our customers to power their journey to AI. Learn more about how Dell Technologies partners with these ISVs in these solution overviews.