VxRail: Die physische Ansicht wird nicht angezeigt, da der Node nicht auf den Befehl "esxcli" reagiert.
Summary: Physische Ansicht des VxRail-Cluster-Node fehlt, Node antwortet nicht auf "esxcli"-Befehl, NTP wird nicht synchronisiert.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
-
Die physischen Ansichten aller Nodes fehlen.
Ab web.log trat beim API-Gateway nach 10 Minuten nach dem Abrufen der physischen Ansichtsdaten eine Zeitüberschreitung auf:2023-11-20T09:24:31.039Z <7527c8d153655e9bbb43b32dcd312443> marvin [ERROR] <261> ApplianceServiceImpl.java populatePvCache() (276): failed to fetch data. javax.ws.rs.ServerErrorException: HTTP 504 Gateway Time-out at org.glassfish.jersey.client.JerseyInvocation.createExceptionForFamily(JerseyInvocation.java:1125) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation.convertToException(JerseyInvocation.java:1105) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation.translate(JerseyInvocation.java:883) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation.lambda$invoke$1(JerseyInvocation.java:767) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.internal.Errors.process(Errors.java:316) ~[jersey-common-2.27.jar:?] at org.glassfish.jersey.internal.Errors.process(Errors.java:298) ~[jersey-common-2.27.jar:?] at org.glassfish.jersey.internal.Errors.process(Errors.java:229) ~[jersey-common-2.27.jar:?] at org.glassfish.jersey.process.internal.RequestScope.runInScope(RequestScope.java:414) ~[jersey-common-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation.invoke(JerseyInvocation.java:765) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation$Builder.method(JerseyInvocation.java:456) ~[jersey-client-2.27.jar:?] at org.glassfish.jersey.client.JerseyInvocation$Builder.post(JerseyInvocation.java:357) ~[jersey-client-2.27.jar:?] at com.vce.commons.domainowner.graphq.DefaultQueryExecutorImpl.doJsonRequestExecution(DefaultQueryExecutorImpl.java:139) ~[commons-7.0.480.jar:?] at com.vce.commons.domainowner.graphq.DefaultQueryExecutorImpl.execute(DefaultQueryExecutorImpl.java:94) ~[commons-7.0.480.jar:?] at com.emc.mystic.manager.graphql.client.host.HostQuery.configuredHosts(HostQuery.java:138) ~[do-host-graphql-client-1.20.41.jar:?] at com.emc.mystic.manager.graphql.client.host.HostQuery.configuredHosts(HostQuery.java:102) ~[do-host-graphql-client-1.20.41.jar:?] at com.vce.commons.domainowner.node.NodeRepository.getAllClusterNodeData(NodeRepository.java:1997) ~[commons-7.0.480.jar:?] at com.emc.mystic.manager.cluster.service.ApplianceServiceImpl.getAllHostData(ApplianceServiceImpl.java:543) ~[classes/:?] at com.emc.mystic.manager.cluster.service.ApplianceServiceImpl.populatePvCache(ApplianceServiceImpl.java:260) ~[classes/:?] at com.emc.mystic.manager.cluster.service.ApplianceServiceImpl.lambda$updateCacheTask$6(ApplianceServiceImpl.java:320) ~[classes/:?] at java.util.concurrent.FutureTask.run(FutureTask.java:264) [?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?] at java.lang.Thread.run(Thread.java:829) [?:?] 2023-11-20T09:24:31.045Z <7527c8d153655e9bbb43b32dcd312443> marvin [INFO] <261> ApplianceServiceImpl.java lambda$updateCacheTask$6() (321): Success to refresh cache for node: <node SN> 2023-11-20T09:24:31.046Z <7527c8d153655e9bbb43b32dcd312443> marvin [INFO] <59> ApplianceDataRoot.java refreshVxRailClusterTag() (289): Skip refreshing VxRail-Cluster-Tag triggered by scheduled job as it has already been done within 15 minutes. 2023-11-20T09:24:31.046Z <7527c8d153655e9bbb43b32dcd312443> marvin [INFO] <59> ApplianceDataRoot.java fetchData() (357): [VXMPERF] PV fetch data execution time in 602 seconds
-
Führen Sie den folgenden Befehl auf dem VxRail Manager aus, um Daten zur physischen Ansicht des Nodes abzufragen:
#curl -X GET --unix-socket /var/lib/vxrail/nginx/socket/nginx.sock http://127.0.0.1/rest/vxm/internal/do/v1/host/query -H 'Content-Type: application/json' -d '{"query":"{ configuredHosts { hardware { sn } } }"}' 2>/dev/null | jq | egrep "name|sn" | awk -F\" '/sn/{print $4}' | sort -u | while read sn; do time curl -X POST --unix-socket /var/lib/vxrail/nginx/socket/nginx.sock -H 'Content-Type: application/json' -d '{"variables":"{\"sn\":\"'${sn}'\"}","query":"query ($sn:[String]){ configuredHosts(sn:$sn) { moid name type summary{ hardware{ cpuNum}} config{ hostUUID isPrimary network{ vnic{ device ipv4 allIpv6s nonLinkLocalIpv6} idrac{ ipAddress ipAddressSource netmask gateway ipAddressV6 gatewayV6 prefixLen ipv6AutoConfig vlan{ enabled id priority}}} localSlotClaims{ slot bay type usage diskgroupId} diskgroup{ slotNum current{ type}} installedComponent{ displayName version model description installedTime}} runtime{ connectionState overallStatus powerState inMaintenanceMode} hardware{ sn psnt slot manufacturer name systemStatusLed tpm model firmware{ id model} firmwareRevisions{ idsdmFwRevision biosFwRevision bmcFwRevision diskCtrlFwRevision bossFwRevision cpldFwRevision expanderBackplane nonExpanderBackplane dcpmFwRevision percDiskCtrlFwRevision} baseline{ sn slot chassisId isMissing} chassis{ name model psnt partNumber serviceTag psus{ sn name slot manufacturer partNumber firmwareVersion baseline{ sn slot isMissing}}} disks{ sn guid capacity slot firmwareVersion diskType diskState manufacturer protocol maxCapableSpeed model ledStatus writeEndurance bay enclosure remainingWriteEnduranceRate encryptionAbility encryptionStatus baseline{ sn slot bay isMissing}} bootDevices{ sn firmwareVersion sataType powerOnHours powerCycleCount avrEraseCount maxEraseCount capacity deviceModel slot health bootDeviceType status blockSizeBytes partNumber manufacturer controllerFirmware controllerModel controllerStatus raidStatus} nics{ mac linkSpeed firmwareFamilyVersion linkStatus fqdd specificNicType wwnn wwpn drivers{ driverName driverVersion}} position{ rackName rackSlot} storageInstance{ securityStatus encryptionMode}}} }","operationName":null}' http://0/rest/vxm/internal/do/v1/host/query; echo ""; echo ""; echo "Done checking $sn"; done -
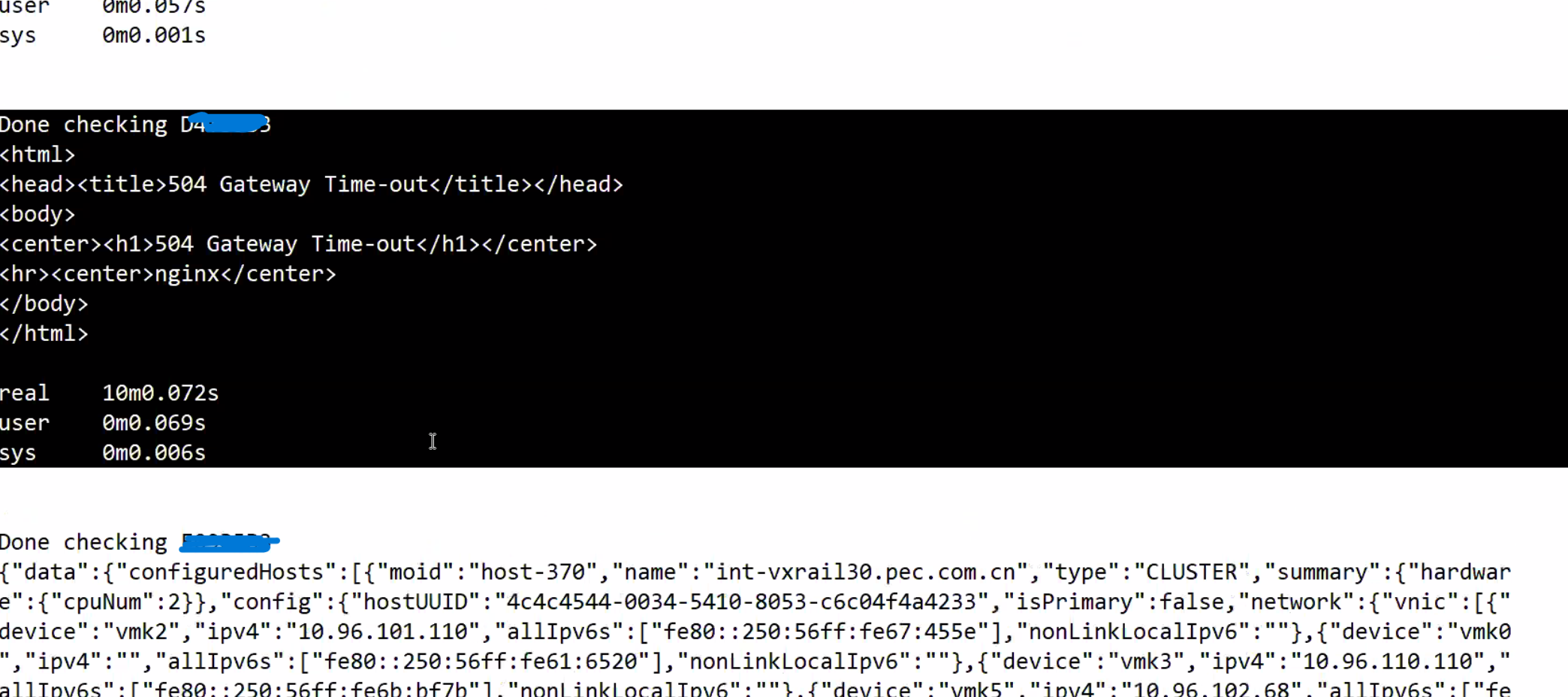
Ergebnis, das anzeigt, dass ein oder mehrere Nodes die Daten nicht innerhalb von 10 Minuten zurückgegeben haben:
Die fraglichen Nodes geben den Fehler "504 Gateway Time-out" zurück, während für funktionierende Nodes korrekte physische Ansichtsdaten zurückgegeben werden.
-
Melden Sie sich basierend auf der wie oben identifizierten Node-SN beim Node an und führen Sie Folgendes aus
esxcliBefehl, es blieb hängen, aber localcli funktioniert:

Cause
Auf dem Node trat ein NTP-Synchronisierungsproblem auf, das zum Fehler esxcli Der Befehl bleibt hängen und es gibt keine Antwort.
Anrufe zur physischen VxRail-Ansicht esxcli Befehle auf dem Node zum Abrufen von Firmware-Informationen, es können die Informationen nicht abgerufen werden, wenn der Node beim Ausführen hängen bleibt esxcli verwenden.
Resolution
Die Lösung besteht darin, das NTP-Synchronisierungsproblem auf allen Nodes zu identifizieren und zu beheben. Befolgen Sie die folgenden Schritte, um den Status von NTP auf Nodes zu überprüfen:
-
Überprüfen Sie /var/log/vobd.log auf Fehlermeldungen, die darauf hinweisen, dass die Systemuhr nicht mehr mit den Upstream-Zeitservern synchronisiert ist.
-
Wenn ja, überprüfen Sie den NTP-Serverstatus.
#ntpq -p

Wenn der Wert für "reach" nicht 377 ist, fehlt dem Host eine NTP-Transaktion. Die Zeit auf diesem ESXi ist möglicherweise falsch und erfordert Aufmerksamkeit.
#ntpq -c
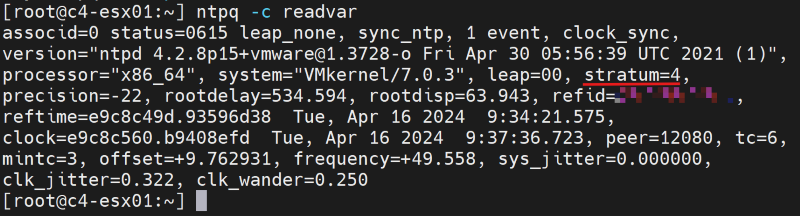
Wenn der Wert "stratum" außerhalb des Bereichs von 2 bis 6 liegt, kann es bei der Zeitsynchronisation auf diesem ESXi zu zusätzlichen Verzögerungen kommen, was möglicherweise zu einer ungenauen Zeitmessung führt.
-
Überprüfen Sie, ob die NTP-Serveradresse in der VxRail Manager-Datenbank mit der API korrekt ist.
curl -k --user "[vCenter account]:[vCenter password]" --request GET "https://localhost/rest/vxm/v1/system/ntp"
-
Falls nicht, befolgen Sie die vorhandenen Anleitungen (VxRail-Verfahren → Verschiedenes → Anleitungen → Ändern von VxRail-IP-Adressen → Neuausrichtung auf eine neue NTP-Server-IP-Adresse), um die NTP-Server-IP-Adresse zu aktualisieren.
-
Verwenden Sie bei Bedarf einen anderen funktionierenden NTP-Server. Starten Sie die Node-vpxa- und Host-Services neu. Beachten Sie, dass ein Neustart der Node-vpxa- und Host-Services das Problem vorübergehend behebt, aber das Problem wiederkehrt, wenn NTP nicht erneut synchronisiert werden kann.
/etc/init.d/vpxa restart /etc/init.d/hostd restart
Affected Products
VxRailArticle Properties
Article Number: 000224344
Article Type: Solution
Last Modified: 24 May 2024
Version: 2
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.